| 논문명 | VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection |
|---|---|
| 저자(소속) | Yin Zhou(Apple) |
| 학회/년도 | arXiv Nov 2017, 논문 |
| Citation ID / 키워드 | Yin2017VoxelNet, LiDAR Only |
| 데이터셋(센서)/모델 | KITTI |
| 관련연구 | |
| 참고 | post, 애플 자율주행차 기술 ‘복셀넷’…최신 라이다 기능 훌쩍 뛰어넘어 |
| 코드 | docker push adioshun/voxelnet,VoxelNet-ROS, TF / Docker, pytorch, TF, |
VoxelNet
- 산재된 LiDAR를 가지고 예측을 수행 하기 위해서 사용된 방법들은 대부분 bird’s eye view projection같은 수작업 특징들을 이용하는 것들이다.
To interface a highly sparse LiDAR point cloud with a region proposal network (RPN), most existing efforts have focused on hand-crafted feature representations, for example, a bird’s eye view projection.
- 본 연구를 통해 Feature 엔지니어링 작업을 없애는 VoxelNet을 제안 한다.
In this work, we remove the need of manual feature engineering for 3D point clouds and propose VoxelNet, - 제안 방식은 특징 추출 및 BBox를 예측을 한번에 진행 할수 있다.
a generic 3D detection network that unifies feature extraction and bounding box prediction into a single stage, end-to-end trainable deep network.
- 특히 VoxelNet은 새롭게 선보이는 VFE(voxel feature encoding) Layer을 이용하여 포인트 클라우드를
equally spaced 3D voxels과transforms a group of points로 나누게 된다. - Specifically, VoxelNet divides a point cloud into equally spaced 3D voxels and transforms a group of points within each voxel into a unified feature representation through the newly introduced voxel feature encoding (VFE) layer.
- 이렇게 함으로써 포인트 클라우드는 설명력을 가지는 volumetric representation로 encode된다.
In this way,the point cloud is encoded as a descriptive volumetric representation, - 이 representation을 PRN에 적용하여 후보 영역을 찾는다.
which is then connected to a RPN to generate detections.
1. Introduction
LiDAR는 많은 분야에 이용되고, 차량주행 등 신뢰성이 보장되는 분야에 적용된다.
하지만, 포인트 클라우드 데이터는 산재되어 있고 아래와 같은 이유로 highly variable point density하다.
LiDAR point clouds are sparse and have highly variable point density, due to factors such as- non-uniform sampling of the 3D space,
- effective range of the sensors,
- occlusion,
and the relative pose.
이렇나 문제를 해결하기 위하여 manually crafted feature representation기법들이 활용 되었다.
`To handle these challenges, many approaches manually crafted feature representations for point clouds that are tuned for 3D object detection.
일부 방법은 포인트 클라우드를 원근법 시점
(perspective view)으로 투영하고 이미지 기반 특징 추출 방식을 적용 하였다.Several methods project point clouds into a perspective view and apply image-based feature extraction techniques[28, 15, 22].
[28] C. Premebida, J. Carreira, J. Batista, and U. Nunes. Pedestrian detection combining RGB and dense LIDAR data. In IROS, pages 0–1. IEEE, Sep 2014.
[15] A. Gonzalez, G. Villalonga, J. Xu, D. Vazquez, J. Amores, and A. Lopez. Multiview random forest of local experts combining rgb and lidar data for pedestrian detection. In IEEE Intelligent Vehicles Symposium (IV), 2015.
[22] B. Li, T. Zhang, and T. Xia. Vehicle detection from 3d lidar using fully convolutional network. In Robotics: Science and Systems, 2016.
- 다른 방법은 포인트 클라우드를 3D voxel grid로 래스터화 하고 각 voxel을 handcrafted features로 encode하였다.
Other approaches rasterize point clouds into a 3D voxel grid and encode each voxel with handcrafted features [41, 9, 37, 38, 21, 5-MV3D].
[41] D. Z. Wang and I. Posner. Voting for voting in online point cloud object detection. In Proceedings of Robotics: Science and Systems, Rome, Italy, July 2015.
[9] M. Engelcke, D. Rao, D. Z. Wang, C. H. Tong, and I. Posner. Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. In 2017 IEEE International Conference on Robotics and Automation (ICRA), pages 1355–1361, May 2017.
[37] S. Song and J. Xiao. Sliding shapes for 3d object detection in depth images. In European Conference on Computer Vision, Proceedings, pages 634–651, Cham, 2014. Springer International
Publishing.
[38] S. Song and J. Xiao. Deep Sliding Shapes for amodal 3D object detection in RGB-D images. In CVPR, 2016
[21] B. Li. 3d fully convolutional network for vehicle detection in point cloud. In IROS, 2017.
[5] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia. Multi-view 3d object detection network for autonomous driving. In IEEE CVPR, 2017.
하지만 이러한 manual 방식들은 정보 Bottlenet을 유발하여 3D shape 정보를 제대로 활용하지 못하게 하고 물체 탐지를 위해서 invariances에 대한 처리 방법을 필요로 한다.
However, these manual design choices introduce an information bottleneck that prevents these approaches from effectively exploiting 3D shape information and the required invariances for the detection task.인지와 탐지 분야의 새로운 도약점(breakthrough )은 수작업 특징 추출에서 기계 학습 기반으로 넘어온 것이다.
A major breakthrough in recognition [20] and detection [13] tasks on images was due to moving from hand-crafted features to machine-learned features.
[PointNet & PointNet ++]
Recently, Qi et al.[29] proposed PointNet, an end-to end deep neural network that learns point-wise features directly from point clouds.
This approach demonstrated impressive results on 3D object recognition, 3D object part segmentation, and point-wise semantic segmentation tasks.
In [30], an improved version of PointNet was introduced which enabled the network to learn local structures at different scales.
좋은 성능을 위하여 위 두 네트워크는 모든 인풋 입력(1k points)들에 대하여 학습을 수행 하였다.
To achieve satisfactory results, these two approaches trained feature transformer networks on all input points (∼1k points).보통 포인트 클라우드로 입련 되는것이 100k point임을 감안 하면 위 방식은 자원 소모가 크다.
Since typical point clouds obtained using LiDARs contain ∼100k points, training the architectures as in [29, 30] results in high computational and memory requirements.Scaling up 3D feature learning networks to orders of magnitude more points and to 3D detection tasks are the main challenges that we address in this paper.
[29] C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2017.
[30] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv preprint arXiv:1706.02413, 2017.
RPN은 물체 탐지에 최적화된 방법이다.
Region proposal network (RPN) [32] is a highly optimized algorithm for efficient object detection [17, 5, 31,24].하지만 이 방식은 입력으로 Dense하고 텐서 구조
(e.g. image, video)로 구성되어 이어야 하기 때문에 LiDAR에 적합하지 않다.However, this approach requires data to be dense and organized in a tensor structure (e.g. image, video) which is not the case for typical LiDAR point clouds.본 논문에서는
point set feature learning와RPN간의 차이를 줄였다.In this paper,we close the gap between point set feature learning and RPN for 3D detection task.
[본 논문의 제안]
- 특징 추출과 물체 탐지를 동시에 수행하는 end-to-end 기반 VoxelNet 제안
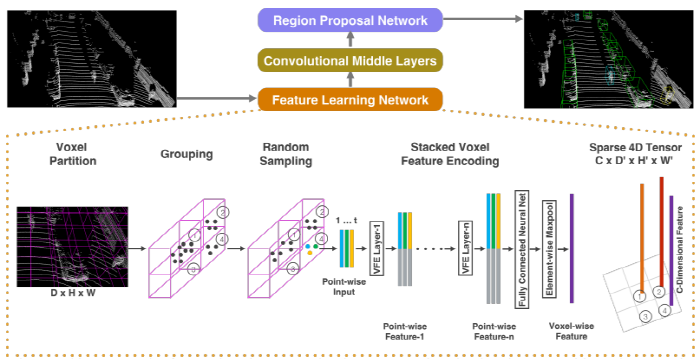
We present VoxelNet, a generic 3D detection framework that simultaneously learns a discriminative feature representation from point clouds and predicts accurate 3D bounding boxes, in an end-to-end fashion, as shown in Figure 2.

[Figure 2. VoxelNet architecture.]
- The feature learning network takes a raw point cloud as input,
- partitions the space into voxels, and transforms points within each voxel to a vector representation characterizing the shape information.
- The space is represented as a sparse 4D tensor.
- The convolutional middle layers processes the 4D tensor to aggregate spatial context.
- Finally, a RPN generates the 3D detection
- VFE 층 제안
We design a novel voxel feature encoding (VFE) layer, which enables point-wise features combine을 통해 Voxel내 포인트간의 상호 작용이 가능
inter-point interaction within a voxel, by combining point-wise features with a locally aggregated feature.VFE 층을 쌓음으로써 성능 향상이 가능하다.
Stacking multiple VFE layers allows learning complex features for characterizing local 3D shape information.Specifically,VoxelNet divides the point cloud into equally
- spaced 3D voxels, encodes each voxel via stacked VFE layers,
and then 3D convolution further aggregates local voxel features, transforming the point cloud into a high-dimensional volumetric representation.
마지막으로 volumetric representation에 RPN을 적용하여 탐지 결과를 출력한다.
Finally, a RPN consumes the volumetric representation and yields the detection result.이 방식은 산재된 포인트 클라우드 구조와 voxel grid의 parallel연산에도 효율적이다.
This efficient algorithm benefits both from the sparse point structure and efficient parallel processing on the voxel grid.
[성능평가]
성능평가는 KITTI데이터셋의 bird’s eye view detection 와 the full 3D detection tasks에 대하여 진행 하였다.
We evaluate VoxelNet on the bird’s eye view detection and the full 3D detection tasks, provided by the KITTI benchmark [11].다른 아이디어 대비 성능 좋다.
Experimental results show that VoxelNet outperforms the state-of-the-art LiDAR based 3D detection methods by a large margin.보행자와 자전거 탐지에도 좋은 성능을 보인다.
We also demonstrate that VoxelNet achieves highly encouraging results in detecting pedestrians and cyclists from LiDAR point cloud.
1.1 Related Work
3D sensor기술의 발전은 detect과 localize을 위한 효율적인 representations개발에 모티브가 되었다.
Rapid development of 3D sensor technology has motivated researchers to develop efficient representations to detect and localize objects in point clouds.초반기의 특징 representations방법들은 다음과 같다.
Some of the earlier methods for feature representation are [39, 8, 7, 19, 40, 33,6, 25, 1, 34, 2].이러한 수작업 특징들은 rich하고 detailed 3D shape information가 있을때는 좋은 성과를 보인다.
These hand-crafted features yield satisfactory results when rich and detailed 3D shape information is available.하지만, 자율 주행 분야 등의 특징에서는 안 좋다.
However their inability to adapt to more complex shapes and scenes, and learn required invariances from data resulted in limited success for uncontrolled scenarios such as autonomous navigation.이미지 데이터가 상세한 texture정보를 제공할수 있으므로 많은 알고리즘은 2D 이미지를 이용하여서 3D B.Box를 예측 한다.
Given that images provide detailed texture information,many algorithms infered the 3D bounding boxes from 2D images [4, 3, 42, 43, 44, 36].하지만 이미지 기반의 3D 탐지 기법은 깊이 예측의 정확도로 인하여 한계가 있다.
However, the accuracy of image-based 3D detection approaches are bounded by the accuracy of the depth estimation.일부 LiDAR기반의 3D 물체 탐지 기법들은 voxel grid representation를 활용한다.
Several LIDAR based 3D object detection techniques utilize a voxel grid representation.[41, 9-Vote3deep] encode each nonempty voxel with 6 statistical quantities that are derived from all the points contained within the voxel.
[41] D. Z. Wang and I. Posner. Voting for voting in online point cloud object detection. In Proceedings of Robotics: Science and Systems, Rome, Italy, July 2015.
[9] M. Engelcke, D. Rao, D. Z. Wang, C. H. Tong, and I. Posner. Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. In 2017 IEEE International Conference on Robotics and Automation (ICRA), pages 1355–1361, May 2017.
- 지역적 통계값 사용 : [37-Sliding shapes]fuses multiple local statistics to represent each voxel.
[37] S. Song and J. Xiao. Sliding shapes for 3d object detection in depth images. In European Conference on Computer Vision, Proceedings, pages 634–651, Cham, 2014. Springer International
Publishing.
- [38]computes the truncated signed distance on the voxel grid.
[38] S. Song and J. Xiao. Deep Sliding Shapes for amodal 3D object detection in RGB-D images. In CVPR, 2016.
- [21] uses binary encoding for the 3D voxel grid.
[21] B. Li. 3d fully convolutional network for vehicle detection in point cloud. In IROS, 2017.
- [5-MV3D] introduces a multi-view representation for a LiDAR pointcloud by computing a multi-channel feature map in the bird’s eye view and the cylindral coordinates in the frontal view.
[5] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia. Multi-view 3d object detection network for autonomous driving. In IEEE CVPR, 2017.
- 일부 연구는 포인트 클라우드를 원점뷰로 투영후 이미지 기반 특징 encode 방법 적용
Several other studies project point clouds onto a perspective view and then use image-based feature encoding schemes [28, 15, 22].
[28] C. Premebida, J. Carreira, J. Batista, and U. Nunes. Pedestrian detection combining RGB and dense LIDAR data. In IROS, pages 0–1. IEEE, Sep 2014
[15] A. Gonzalez, G. Villalonga, J. Xu, D. Vazquez, J. Amores, and A. Lopez. Multiview random forest of local experts combining rgb and lidar data for pedestrian detection. In IEEE
Intelligent Vehicles Symposium (IV), 2015.
[22] B. Li, T. Zhang, and T. Xia. Vehicle detection from 3d lidar using fully convolutional network. In Robotics: Science and Systems, 2016.
- 이미지와 LiDAR를 합치는 멀티 모달 방식
There are also several multi-modal fusion methods that combine images and LiDAR to improve detection accuracy[10, 16, 5].
[10] M. Enzweiler and D. M. Gavrila. A multilevel mixture-ofexperts framework for pedestrian classification. IEEE Transactions on Image Processing, 20(10):2967–2979, Oct 2011
[16] A. Gonzlez, D. Vzquez, A. M. Lpez, and J. Amores. Onboard object detection: Multicue, multimodal, and multiview random forest of local experts. IEEE Transactions on Cybernetics,
47(11):3980–3990, Nov 2017.
[5] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia. Multi-view 3d object detection network for autonomous driving. In IEEE CVPR, 2017.
이러한 방식들은 작은 물체는 멀리 있는 물체를 탐지 하는데는 3D만 사용 하는 방식 보다는 성능이 좋.
These methods provide improved performance compared to LiDAR-only 3D detection, particularly for small objects (pedestrians, cyclists) or when the objects are far, since cameras provide an order of magnitude more measurements than LiDAR.그러나 카메라를 사용하게 되면 싱크 시간이나 칼리브레이션 이 필요 하며 둘중 하나의 센서가 고장 나는 위험도 있다.
However the need for an additional camera that is time synchronized and calibrated with the LiDAR restricts their use and makes the solution more sensitive to sensor failure modes.따라서 본 논문은 라이다만 고려 한다.
In this work we focus onLiDAR-only detection.
1.2 Contributions
산재된 3D points에 바로 동작 하여 메뉴얼한 피쳐 엔지니어링 불필요
We propose a novel end-to-end trainable deep architecture for point-cloud-based 3D detection, VoxelNet,that directly operates on sparse 3D points and avoids information bottlenecks introduced by manual feature engineering.We present an efficient method to implement VoxelNet which benefits both from the
- sparse point structure and
efficient parallel processing on the voxel grid.
성능 평가 결과 좋음
We conduct experiments on KITTI benchmark and show that VoxelNet produces state-of-the-art results in LiDAR-based car, pedestrian, and cyclist detection benchmarks.
2. VoxelNet
2.1 VoxelNet Architecture
- VoxelNet은 3가지 요소로 구성 되어 있다.
The proposed VoxelNet consists of three functional blocks: - (1) Feature learning network,
- (2) Convolutional middle layers, and
- (3) Region proposal network [32]
A. Feature Learning Network

[Voxel Partition]
Given a point cloud, we subdivide the 3D space into equally spaced voxels as shown in Figure 2.
Suppose the point cloud encompasses 3D space with range D,H, W along the Z, Y, X axes respectively.
We define each voxel of size $$v_D$$, $$v_H$$, and $$v_W$$ accordingly.
The resulting 3D voxel grid is of size $$D\prime = \frac {D}{v_D}, H\prime = \frac{H}{v_H}, W\prime= \frac{W}{v_W}$$ .
Here, for simplicity, we assume D, H, W are a multiple of $$v_D, v_H, v_W$$ .
[Grouping]
- 복셀 단위로 포인트 들을 그룹핑
We group the points according to the voxel they reside in.
- 아래 특징으로 포인트 클라우드는 산재 되어 있고 highly variable point density하다.
Due to factors the LiDAR point cloud is sparse and has highly variable point density throughout the space. - Factors = such as distance, occlusion, object’s relative pose, and non-uniform sampling,
- 따라서 그룹핑후 복셀은 포인트에 대한 variable number을 가지게 된다.
Therefore, after grouping, a voxel will contain a variable number of points. - 그림 2에서는 복셀 1이 포이트가 가장 많고, 복셀 3은 하나도 없다.
An illustration is shown in Figure 2, where Voxel-1 has significantly more points than Voxel-2 and Voxel-4, while Voxel-3 contains nopoint
[Random Sampling]
일반적으로 고밀도 LiDAR는 ~100k개의 포인트로 구성된다.
Typically a high-definition LiDAR point cloud is composed of ∼100k points.모든 포인트를 모두 계산에 고려 하는것은 부하가 크다. 또한 highly variable point density한것은 탐지에 영향
(bias)을 미칠수 있다.Directly processing all the points not only imposes increased memory/efficiency burdens on the computing platform, but also highly variable point density throughout the space might bias the detection.따라서 복셀에 t개 이상의 포인트가 있다면, t개의 샘플들만 선택 하여 사용한다.
To this end, we randomly sample a fixed number, T, of points from those voxels containing more than T points.이 샘플링의 목적은 다음과 같다.
This sampling strategy has two purposes,- (1) 계산 부하
computational savings (see Section 2.3 for details); and - (2) 복셀간 포인트 불균형 문제 해결
decreases the imbalance of points between the voxels which reduces the sampling bias, and adds more variation to training.
[Stacked Voxel Feature Encoding ]
가장 중요한 요소는
VFE layers.이다.The key innovation is the chain of VFE layers.For simplicity, Figure 2 illustrates the hierarchical feature encoding process for one voxel.
Without loss of generality, we use VFE Layer-1 to describe the details in the following paragraph.
Figure 3 shows the architecture for VFE Layer-1.

- V는 t개이상의 포인트를 가진 비어 있지 않은 복셀인다.
- Denote $$V= { pi = \left[ x_i, y_i, z_i, r_i\right]^T \in \Re^4 }{i=1...t}$$ as a non-empty voxel containing t ≤ T LiDAR points,
- where $$p_i$$ contains XYZ coordinates for the i-th point and $$r_i$$ is the received reflectance.
- 먼저 local mean을 구하여 V에 있는 모든 포인트의 Centroid값으로 정한다.
- We first compute the local mean as the centroid of all the points in V,
- denoted as $$(v_x, v_y, v_z)$$.
- 다음, centroid와 입력 특징셋 $$V_{in}$$를 기반으로 포인트를 증폭시킨다.
- Then we augment each point $$p_i$$ with the relative offset
- w.r.t. the centroid and obtain the input feature set $$ V{in} = {\hat p_i = \left[x_i, y_i, z_i, r_i, x_i − v_x, y_i −v_y, z_i −v_z\right]^T \in \Re^7}{i=1...t}$$
- 다음 $$\hat p_i$$는 FCN을 이용하여 특징공간으로 변환 된다. 이공간에서 포인트 특징에서 얻은 정보를 shape로 encode한다.
- Next, each $$\hat p_i$$ is transformed through the fully connected network (FCN) into a feature space,
- where we can aggregate information from the point features $$f_i \in \Re^m$$ to encode the shape of the surface contained within the voxel.
- FCN의 구성
The FCN is composed of - a linear layer,
- a batch normalization (BN) layer,
- and a rectified linear unit (ReLU) layer.
point-wise feature representations를 획득후 $V$에 연관된 모든 $$f_i$$에 대하여element-wise MaxPooling를 적용하여 V에 대한 locally aggregated feature를 획득 한다.- After obtaining point-wise feature representations, we use element-wise MaxPooling across all $$f_i$$ associated to $V$ to get the locally aggregated feature $$\tilde{f} \in \Re^m$$ for V.
- 마지막으로 Finally, we augment each $$f_i$$ with $$\tilde{f}$$ to form the point-wise concatenated feature as $$f^{out}_i = \left[f^T_i, \tilde{f}^T \right]^T \in \Re^{2m}$$.
- 결과적으로 아웃푹 특징셋을 얻게 된다.
- Thus we obtain the output feature set $$V{out} = { f^{out}_i}{i...t}$$.
비어 있지 않은 복셀들은 모두 같은 절차를 적용 받고 동일한 파라미터 셋을 공유 한다.
All non-empty voxels are encoded in the same way and they share the same set of parameters in FCN.i번째 VFE층으로 표현되는$$VFE-i(c{in}, c{out})$$는 입력 특징의 차원을 출력 특징의 차원으로 변경한 것이다.
- We use $$VFE-i(c{in}, c{out})$$ to represent the i-th VFE layer that transforms input features of dimension $$c{in}$$ into output features of dimension $$c{out}$$.
- 선형층은 $$c{in} \times ( c{out} / 2 )$$크기의 매트릭스를 학습하고 point-wise concatenation은 $$c_{out}$$차원의 결과물을 출력한다.
- The linear layer learns a matrix of size $$c{in} \times ( c{out} / 2 )$$, and thepoint-wise concatenation yields the output of dimension $$c_{out}$$.
- 출력 특징은 point-wise features와 locally aggregated feature를 합친 것이기 때문에
`Because the output feature combines both point-wise features and locally aggregated feature, stacking VFE layers encodes point interactions within a voxel and enables the final feature representation to learn descriptive shape information.
복셀 단위 특징
(voxel-wise feature)은 FCN과 element-wise Maxpool을 이용하여 출력 $$VFE-n$$을 $$\Re^C$$로 변환하여 얻은 것이다.- The voxel-wise feature is obtained by transforming the output of $$VFE-n$$ into $$\Re^C$$ via FCN and applying element-wise Maxpool where C is the dimension of the voxel-wise feature, as shown in Figure 2.
[Sparse Tensor Representation]
- 하나의 복셀에 대한 연산을 통해 복셀 특징 리스트를 얻게 된다.
By processing only the non-empty voxels, we obtain a list of voxel features, 각각은 복셀의 공간적 좌표와 연결되어 있다.
each uniquely associated to the spatial coordinates of a particular non-empty voxel.얻은 복셀 특징 리스트는 4D Tensor로 표현된다.
The obtained list of voxel-wise features can be represented as a sparse 4D tensor, of size $C × D \prime× H \prime × W \prime$ as shown in Figure 2.
비록 포인트 클라우드가 ∼100k points로 구성되어 있지만 90%는 비어 있는 것이다.
Although the point cloud contains ∼100k points, more than 90% of voxels typically are empty.비어있지 않는 복셀 특징을 sparse tensor표현하는것은 효율화 측면에서 좋다.
Representing non-empty voxel features as a sparse tensor greatly reduces the memory usage and computation cost during backpropagation, and it is a critical step in our efficient implementation.
B. Convolutional Middle Layers
- 합성곱 연산 : We use ConvMD($$c{in}, c{out}, k, s, p$$) to represent an M-dimensional convolution operator
- 입출력 채널: where $$c{in}$$ and $$c{out}$$ are the number of input and output channels,
- 파라미터 : k(kernel size), s(stride size), and p(padding size) are the M-dimensional vectors
- 크기는 모두 동일함 When the size across the M-dimensions are the same, we use a scalar to represent the size e.g. k for k = (k, k, k).
- 각 합성곱 중간 레이어는 다음 절차를 순서대로 진행 한다. Each convolutional middle layer applies
- 3D convolution,
- BN layer, and
- ReLU layer sequentially.
The convolutional middle layers aggregate voxel-wise features within a progressively expanding receptive field, adding more context to the shape description.
The detailed sizes of the filters in the convolutional middle layers are explained in Section 3
C. Region Proposal Network
- 최근 RPN은 물체 탐지에서 중요한 구성 요소이다.
Recently, region proposal networks [32-Faster R-CNN] have become an important building block of top-performing object detection frameworks [38, 5, 23].
[38] S. Song and J. Xiao. Deep Sliding Shapes for amodal 3D object detection in RGB-D images. In CVPR, 2016. 1
[5] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia. Multi-view 3d object detection network for autonomous driving. In IEEE CVPR, 2017.
[23] T. Lin, P. Goyal, R. B. Girshick, K. He, and P. Dollar. Focal ´loss for dense object detection. IEEE ICCV, 2017.
본 연구에서는 RPN의 일부분을 수정하여 적용 하였다.
In this work, we make several key modifications to the RPN architecture proposed in [32] ,and combine it with the feature learning network and convolutional middle layers to form an end-to-end trainable pipeline.RPN의 입력은 합성곱 중간 층에서 제공되는 특징맵이다.
The input to our RPN is the feature map provided by the convolutional middle layers.
- The architecture of this network is illustrated in Figure 4.

- 네트워크는 3개의 FCL 블럭으로 이루어져 있다.
The network has three blocks of fully convolutional layers. - The first layer of each block down samples the feature map by half via a convolution with a stride size of 2, followed by a sequence of convolutions of stride 1 (×q means q applications of the filter). After each convolution layer, BN and ReLU operations areapplied.
- We then upsample the output of every block to a fixed size and concatanate to construct the high resolution feature map.
- Finally, this feature map is mapped to the desired learning targets: (1) a probability score map and (2) a regression map.
2.3 Loss Function
- Let $$ { a^{pos}i}{i=1...N_{pos}} $$ be the set of N_pos positive anchors
$$ { a^{neg}j}{j=1...N_{neg}}$$ be the set of N_neg negative anchors.
We parameterize a 3D ground truth box as $$(x^g_c, y^g_c, z^g_c, l^g, w^g, h^g, \theta^g)$$
- where $$(x^g_c, y^g_c, z^g_c$$ represent the center location,
- $$l^g, w^g, h^g$$ are length, width, height of the box
$$\theta^g$$ is the yaw rotation around Z-axis.
To retrieve the ground truth box from a matching positive anchor parameterized as $$(x^a_c, y^a_c, z^a_c, l^a, w^a, h^a, \theta^a)$$ , we define the residual vector $$ u\star \in \Re^7$$ containing the 7 regression targets corresponding to center location ∆ x, ∆y, ∆z three di-mensions ∆l, ∆w, ∆h, and the rotation ∆θ, which are computed as:

2.4 Efficient Implementation

3. Training Details
3.1. Network Details
A. Car Detection
B. Pedestrian and Cyclist Detection
3.2. Data Augmentation (3D 포인트 클라우드 데이터 증폭 방법)
4000개의 학습 데이터는 오버 피팅 위험성이 있으므로 데이터 증폭 필요
With less than 4000 training point clouds, training our network from scratch will inevitably suffer from overfitting.본 논문에서는 3가지 형태의 방법 사용
To reduce this issue, we introduce three different forms of data augmentation.The augmented training data are generated on-the-fly without the need to be stored on disk [20].
A. 첫번째 방법
- The first form of data augmentation applies perturbation independently to each ground truth 3D bounding box together with those LiDAR points within the box
B. 두번째 방법
- Secondly, we apply global scaling to all ground truth boxes $$b_i$$ and to the whole point cloud M
C. 세번쨰 방법
- Finally, we apply global rotation to all ground truth boxes $$b_i$$ and to the whole point cloud M.
3D Data Augmentation방법에 대하여 조사 하고 이를 적용시 성능향상에 대한 논문 찾아 보기
4. Experiments
5. Conclusion
기존 방식은 수작업 특징에 의존 하였다.
Most existing methods in LiDAR-based 3D detection rely on hand-crafted feature representations, for example,a bird’s eye view projection.본 논문에서는 수작업 피쳐 엔지니어링을 제거한 VoxelNet를 제안 하였다.
In this paper, we remove the bottleneck of manual feature engineering and propose VoxelNet,a novel end-to-end trainable deep architecture for point cloud based 3D detection.
제안 방식은 산재된 3D데이터에 바로 적용 가능하다.
Our approach can operate directly on sparse 3D points and capture 3D shape information effectively.또한 이를 구현 하였다.
We also present an efficient implementation of VoxelNet that benefits from point cloud sparsity and parallel processing on a voxel grid.실험 결과 성능이 좋다.
Our experiments on the KITTI car detection task show that VoxelNet outperformsstate-of-the-art LiDAR based 3D detection methodsby a large margin.어려운 도전중 하나인 보행자와 자전거 인식도 잘된다.
On more challenging tasks, such as 3D detection of pedestrians and cyclists, VoxelNet also demonstrates encouraging results showing that it provides a better 3D representation.향후 이미지와의 결합을 통한 성능 향상을 진행 할 예정이다.
Future work includes extending VoxelNet for joint LiDAR and image based end-to-end 3D detection to further improve detection and localization accuracy
Implementation (TF)
qianguih/voxelnet 코드 기반
- 학습시 이미지 데이터가 필요한 이유 : KITTI는 Lidar에 대하여 label데이터 미 제공, 이미지 데이터 기반 크로핑 [출처]
해당 코드로는 사람 탐지를 위해 추가 되어야 하는 부분(anchor box)이 있음 [출처]
validation 데이터 확보 방안 [출처]