Data Preparation
- 목표
- 모델링 도구의 입력이 될 최종 데이터를 원시 데이터로부터 추출
- Actions
- Select Data : 분석에 사용할 데이터를 선별
- Clean Data : 분석 기법에서 요구한 수준으로 데이터의 품질을 향상
- Construct Data : 분석을 위한 구조화된 데이터 준비
- Integrate Data : 분석을 위해 여러 테이블에서 데이터를 통합
- Format Data : 사용하려는 모델에 적합하도록 데이터의 구문 수정
- KDD : 데이터 - (추출) 목표 데이터 - (전처리) 사전처리 데이터
- Process 2 : 데이터 입력 -> 데이터 확인
The data preparation phase covers all activities to construct the final dataset (data that will be fed into the modeling tool(s)) from the initial raw data. Data preparation tasks are likely to be performed multiple times, and not in any prescribed order. Tasks include table, record, and attribute selection as well as transformation and cleaning of data for modeling tools.
데이터 Preparation단계는 다시 두 단계로 나눌수 있다.
전처리 :수집한 데이터를 저장소에 적재하기 위한 작업으로 데이터 필터링, 유형 변환, 정제 등 기술 활용
후처리 : 저장된 데이터를 분석이 용이하도록 가공하는 작업으로 변환, 통합, 축소 등 기술 활용
| 분류 | 설명 | |
|---|---|---|
| 데이터 여과 (Filtering) | .오류 발견, 보정, 삭제 및 중복성 확인 등의 과정을 통해 데이터 품질을 향상 시키는 기술 | |
| 데이터 변환(Transformation) | -데이터 유형 변환 등 데이터 분석이 용이한 형태로 변환하는 기술 -정규화(normalization), 집합화(Aggregation), 요약(summarization), 계층 생성 등의 방법활용. ETL(extraction/transformation/loading) 도구 제공중 |
|
| 데이터 정제(Cleansing) | . 결측치들을 채워 넣고, 이상치를 식별 또는 제거하고, 잡음 섞인 데이터를 평활화하여 데이터의 불일치성을 교정하는 기술 ※ 일반적으로 데이터는 불완전하고, 잡음이 섞여있고, 일관성이 없기 때문에 데이터 정제가 필요 | |
| 데이터 통합(Integration) | . 데이터 분석이 용이하도록 유사 데이터 및 연계가 필요한 데이터(또는 DB)들을 통합하는기술 | |
| 데이터 축소(Reduction) | . 분석 컴퓨팅 시간을 단축할 수 있도록 데이터 분석에 활용되지 않는 항목 등을 제거하는기술 |
- 데이터 여과 : 중복성, 오류 제거, 저품질 제거
- 데이터 변환 : 다양한 형식에서 일관성 있는 형식으로 변환(분석 용의성 위해)
- 평활화(Smoothing) : 데이터로부터 잡음을 제거하기 위해 데이터 추세에 벗어나는 값들을 변환 (cf. outliner)
- 집계(Aggregation) : 다양한 차원의 방법으로 데이터를 요약
- 일반화(Generalization) : 특정 구간에 분포하는 값으로 스케일을 변화
- 정규화(Normalization) : 데이터에 대한 최소-최대 정규화, z-스코어 정규화, 소수 스케일링 등 통계적 기법 적용
- 속성 생성(Attribute/feature construction) : 데이터 통합을 위해 새로운 속성이나 특징을 만드는 방법으로 주어진 여러 데이터 분포를 대표할 수 있는 새로운 속성/특징 활용
- 데이터 정제 :수집된 데이터의 불일치성을 교정하기 위한 방식으로 결측치(Missing Value) 처리, 잡음(Noise) 처리 기술 활용

데이터 통합 : 출처가 다른 상호 연관성이 있는 데이터들을 하나로 결합하는 기술로 다음 사항들을 고려
- 데이터 통합 시 동일한 데이터가 입력 될 수 있으므로 연관관계 분석 등을 통해 중복 데이터를 검출 할 것
- 데이터 통합 전·후 수치·통계 등 데이터 값들이 일치 할 수 있도록 검증
- 통합 대상 entity가 통합 이후에 동일한지 여부를 확인하기 위한 동일성 검사 수행
- 표현 단위(파운드와 kg, inch와 cm, 시간 등) 등 서로 다른 방식에 대해 표현을 일치할 수 있도록 변환
데이터 축소 : 분석에 불필요한 데이터를 축소하여 고유한 특성은 손상되지 않도록 하고 분석에 대한 효율성을 증대

1. Select Data
Feature selection method (추천 논문 : http://goo.gl/3dz8Ar)
- Filter : 결과변수와 상관계수 같은 통계량이나 척도에 기반한 순위에 따라 가능한 특징을 정렬 .
- eg) 매번 p값, r-제곱을 파악하고 낮은 P-값이나 높은 R-제곱값에 따라 순위를 매김 –
Wrapper : 어떤 고정된 크기의 특징들의 부분 집합을 찾고자 한다.
- 고려 요소 1 : 특징들을 선택하기 위해 사용하는 알고리즘 선택
- 전진 선택(Forward Selection) =
- 후진 제거(Backward Elimination)
- 단계적 방법(Stepwise selection)
- 고려 요소 2 : 특징들의 집합을 '좋다'고 판단하기 위한 필터나 선택 기준 결정
- R제곱값 = 모형에 의해 설명되는 분산의 비율
- P 값 = 가정된 귀무가설이 관찰값을 이용하여 얻게될 확률
- 아케이케 정보기준(AIC) = 2k -2nl(L) = 2(모수의 개수) -2(로그가능도의 최댓값)
- 베이지안 정보기준(BIC) = Kln(n) - 2ln(L) = (모수의개수)ln(관측값의개수) - 2(로그가능도의 최댓값)
- 엔트로피 = 무엇이 어마나 혼합되어 있는지에 대한 척도
변수 선택(모델링에 적합한 변수만 선택 )
- 필터(filter) 방법 : 데이터의 통계적 특성으로 부터 변수 선택
- 통계적 특성 = 상호 정보량, 상관계수
- Caret::nearZeroVar() : 데이터에서 분산이 0에 가까운 변수를 찾는다.
- Caret::findcorrelation() : 차원저주를 피하기 위해 상관 계수가 낮은 변수를 찾는다.
- 래퍼(Wrapper) 방법 : 변수의 일부만을 모델링에 사용하고 그 결과를 확인 하는 작업을 반복 하면서 선택
- 임베디드(Embedded) 방법 : 모델 자체에 변수 선택이 포함된 방법 (ex: LASSO)
차원 저주(Curse of Dimensionality)
- 상관계수가 높은 변수가 여럿 존재하여 파라미터 수가 불필요하게 증가 하는 현상
- 선형모델, 신경망등의 기계학습에서 상관계수가 큰 예측 변수가 있을경우 성능이 떨어지거나, 모델이 불안정해짐 해결법 :
- PCA를 이용하여 서로 독립된 차원으로 변환,
- 상관계수가 큰 변수 제거, Caret::findcorrelation(), Fselector::linear.correlation() *카이제곱 검정을 사용한 독립성 검증 & 변수 선택, Fselector::chi.squared())
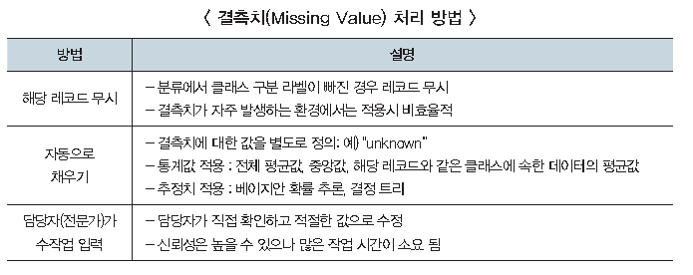
# 모델을 사용한 변수 중요도 계산 : caret::varlmp()
2. Clean Data
2.1 이상치 (Outlier)
A. 이상치 찾기
- 잔차, 특히 외면 스튜던트화 잔차(Externally Studentized Residual) 이용,
rstudent(): 외면 스튜던트화 잔차를 구한다.
- 본페로니(Bonferroni) :
car::outlinerTest(): 이상값 검정 수행
B. 이상치 처리
2.2 결측치
A. 결측치 찾기
- 결측값이 총 몇 개인지 계산하는 방법: sum(is.na()), table(is.na())
- 관측값에 결측치가 없는지를 테스트하며, 반환 값은 관측값에 결측치가 있으면 FALSE, 없으면 TRUE가 된다. complete.cases()
- 그래프를 이용한 찾기 Amelia()
B. 결측치 처리
방식마다 사용 방법이 다름
- rpart - surrogate변수
- 랜덤 포레스트 - randomForest::rfImpute()
가. 삭제
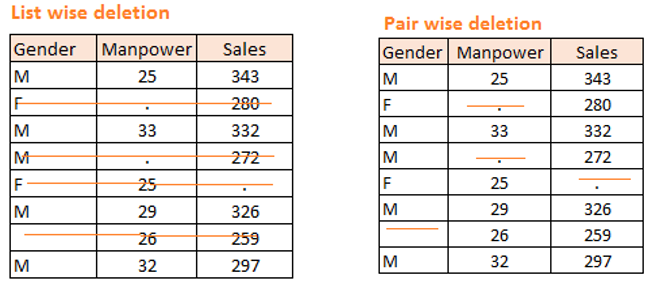
- Delection(List wise delection) : 빈값이 있는행 삭제, 간편함, 샘플수 줄어듬의 단점
- ld(data)
- 결측값이 들어있는 행 전체를 데이터 셋에서 제거: test <- na.omit(test)
- Delection(pair wise delection) :
- 특정 행과 열에 결측값이 들어있는 행을 데이터 셋에서 제거 : complete.cases()
나. 대체
- NA를 가운데 값(central value)로 대체 한다.
DMwR::centralInputation() - NA를 K최근 이웃 분류 알고리즘을 이용해 대체 한다.
DMwR::knnImputation() - NA를 다른 값으로 대체한다.
dataset$var[is.na(dataset$var)] <- new_value - NULL/NA -> 0으로 변경
test2$lesson_time <- as.character(test2$lesson_time) test2$lesson_time2 <- sub("NULL","0",test2$lesson_time)
[참고]
http://www.analyticsvidhya.com/blog/2015/02/7-steps-data-exploration-preparation-building-model-part-2/ http://rfriend.tistory.com/34
VIM : http://cran.r-project.org/web/packages/VIM/index.html PISA : http://jbryer.github.com/pisa http://www.r-bloggers.com/visualizing-missing-data-3/
[결측치 비중에 따른 해결법](http://blog.naver.com/jinwon_hong/140160442723)
* 결측치 ~ 10% : 제거, 대치법(Imputation of missing Data)
* 결측치 10~20% : Hot deck cast substitution, regression, modell-based methods
* 결측치가 20%~ : egression, model-based mehod
3. Construct Data
3.1 데이터 정규화(Feature Scaling)
- 변숫값의 분포를 표준화 하는 것
- 표준화 = 변수에서 데이터의 평균을 빼거나 or 변수를 전체 데이터의 표준 편차로 나누는 작업
- 결과 : 변수값이 평균이 0이 되고, 값의 분포가 일정해짐
- Scale()함수 사용 : as.data.frame(scale(iris[1:4]))
Scaling and Centering of Matrix-like Objects
- Centering = 관측치 – 평균
- 척도 변환
- 다른 변수와의 비교를 위하여
Scale (x, center = TRUE, scale = TURE)
- X : a numeric matrix(like object).
- Center : either a logical value or a numeric vector of length equal to the number of columns of x.
- Scale : either a logical value or a numeric vector of length equal to the number of columns of x.
Center = 평균이 0이 되게 함, Scale = 분산이 1이 되게함
3.3 주성분 분석(PCA)
- 데이터에 많은 변수가 있을 때 변수의 수를 줄이는 차원 감소 기법
3.4 원 핫 인코딩(One Hot Encoding)
- 범주형 변수의 Level을 줄이는 작업
- 여러 가변수를 이용해 범주형 변수를 재 표현
- model.matrix() 를 사용해 구할수 있음
랜덤 포레스트의 경우 32개 이하 Level만 지원하므로 넘는 다면 OHE가 필수적