Data Understanding
- 목표
- 초기 데이터를 수집, 이해하고 데이터의 품질을 정의하고 몇가지 가설을 구성하기 위한 데이터셋을 설정
- Actions
- Collect Initial Data : 초기 데이터를 수집
- Describe Data : 수집된 데이터의 특성을 확인
- Explore Data : 질의, 시각화, 보고서 등 데이터 마이닝 목표에 부합하는 데이터 추출
- Verify Data Quality : 데이터의 품질 검사
- 문제 해결을 위해 어떤 데이터를 사용하여야 하는가?
- 문제 해결을 위한 데이터 이면에 숨겨져 있는 원리는?
- 변수 선정
The data understanding phase starts with an initial data collection and proceeds with activities in order to get familiar with the data, to identify data quality problems, to discover first insights into the data, or to detect interesting subsets to form hypotheses for hidden information.
1. Collection Initial Data
1.1 다양한 소스에서 데이터 수집 하기
1.2 Sampling
수집된 데이터 중에서 테스트용과 검증용으로 7:3(일반적)으로 나누기
A. 단순 임의 추출
- 각 데이터를 추출할 확률을 동일하게 하여 표본을 추출하는 방법
- 복원 추출
- 비복원 추출
- 가중치 적용이 필요 할 경우
prob파라미터 설정
#sample()
B. 층화 임의 추출
- 데이터가 중첩 없이 분활될수 있는 경우/성격이 명확히 다를 경우 수행 하면 더 정확한 분석 결과를 얻을수 있다.
- eg: 남성과 여성으로 나누(=층)어서 표본 추출
# sampleing::strata()
# 파라미터중 Poisson은 포아송 추출로 각 데이터의 추출 확률을 다르게 설정하고 각 데이터를 독립적으로 추출하는 경우 설정
C. 계통 추출
- 순서/시간의 영향이 있는 데이터의 경우 $$k$$번째 항목을 추출하는 방법
- eg: 아침부터 밤까지 지나간 차량의 넘버 추출
#doBy 패키지 sampleBy()
클래스 불균형(Class Imbalance)
- 구분할 각 분류에 해당하는 데이터의 비율이 반반이 아닌 경우 데이터가 많은쪽으로 결과가 치우침
- 해결법_1 : 데이터가 적은쪽에 가중치 or 데이터가 적은쪽을 잘못 분류시 Cost/Loss 부과 (모델링 함수의 param, loss, cost파라미터 이용)
- 해결법_2 : 모델을 만드는 훈견 데이터를 직접 조정 (Up sampling, Down Sampling, Hybrid-SMOTE)
- Up sampling : 데이터가 적은쪽을 표본으로 더 많이 추출
- Down Sampling : 데이터가 많은 쪽을 적게 추출
- downSample(설명변수, 예측대상 분류인자) #d <- downSample(r435, r435$lecture)
- SMOTE : KNN을 이용하여 낮은 분류으 ㅣ데이터 생성
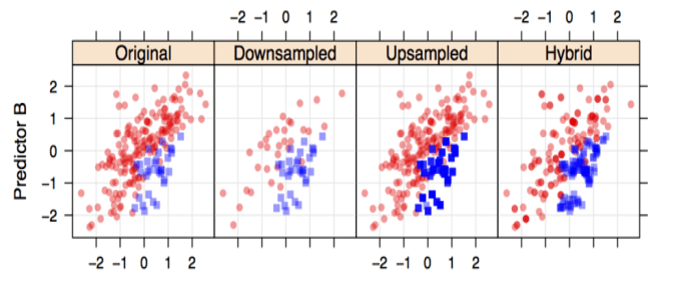 http://www.r-bloggers.com/down-sampling-using-random-forests/
http://www.r-bloggers.com/down-sampling-using-random-forests/
2. Describe Data
3. Explore Data
4. Verfy Data Quality
이상치
이상 관측치(Unusual Observation) 판단하기
- 정의 : An observation that lies an abnormal distance from other values in a random sample from a population
이상치(Outliner)를 파악 하는 방법
- 일변량 : 표준점수(즉, z-score)가 2.5~4 이상인 표본(표본수에 따라 기준은 달라짐) - outliers()
- 이변량 : 산포도를 이용하여 독립변수와 종속변수의 관계성 테스트하여 특정 신뢰구간에 포함되지 않은 표본 - mvoutlier() , corr.plot() 사용
- 다변량 : 마하로노비스 D2 값을 이용, D2/df가 2.5~4이상인 표본(표본수에 따라 기준은 달라짐) - library(chemometrics) - Moulier()
- 큰지레점(High-leverage observation)
- 영향관측치(Influential observation)
이상 관측치 판단하기 : http://blog.naver.com/ilustion/220285462430
이상치 : http://blog.naver.com/jinwon_hong/140160660331
Outlier : http://www.itl.nist.gov/div898/handbook/prc/section1/prc16.htm http://blog.naver.com/jinwon_hong/140160660331 https://en.wikibooks.org/wiki/Data_Mining_Algorithms_In_R/Classification/Outliers
https://www.youtube.com/watch?v=ckxEZDN1iok
http://www.dbs.ifi.lmu.de/~zimek/publications/KDD2010/kdd10-outlier-tutorial.pdf
http://www.r-statistics.com/2011/01/how-to-label-all-the-outliers-in-a-boxplot/
http://blog.naver.com/jinwon_hong/140160660331 https://en.wikibooks.org/wiki/Data_Mining_Algorithms_In_R/Classification/Outliers