Deep Reinforcement Learning for Motion Planning
1. 강의 목적
- DeepTraffic에 대하여 살펴보기
2. 머신러닝 종류
- Supervised Learning
- Unsupervised Learning
- Semi-Supervised Learning
- Reinforcement Learning
3. The process of Learning
Perceptron: Implement a NAND Gate 구현 가능
- NAND gate가 정상 동작 한다면 어떤 logical function도 만들수 있으므로 중요
Learning is the process of gradually adjusting the weights and Seeing how it has an effect on the rest of the network
4. Feed-Forward Neural Network
5. Reinforcement Learning
Philosophical Motivation for Reinforcement Learning
- Takeaway from Supervised Learning: Neural networks are great at memorization and not (yet) great at reasoning.
- Hope for Reinforcement Learning: Brute-force propagation of outcomes to knowledge about
statesandactions.- This is a kind of brute-force “reasoning”
5.1 Agent and Environment
At each step the agent:
- Executes action
- Receives observation (new state)
- Receives reward
The environment:
- Receives action
- Emits observation (new state)
- Emits reward
Reinforcement learning is a general-purpose framework for decision-making:
- An agent operates in an environment: Atari Breakout
- An agent has the capacity to act
- Each action influences the agent’s future state
- Success is measured by a reward signal
- Goal is to select actions to
maximize future reward
Markov Decision Process 와의 유사점 차이점 알아보기
Major Components of an RL Agent
- Policy: agent’s behavior function
- Value function: how good is each state and/or action
- Model: agent’s representation of the environment
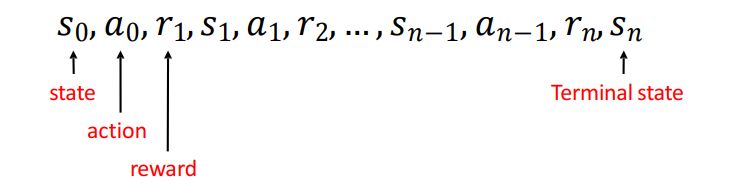
5.2 Robot in a Room
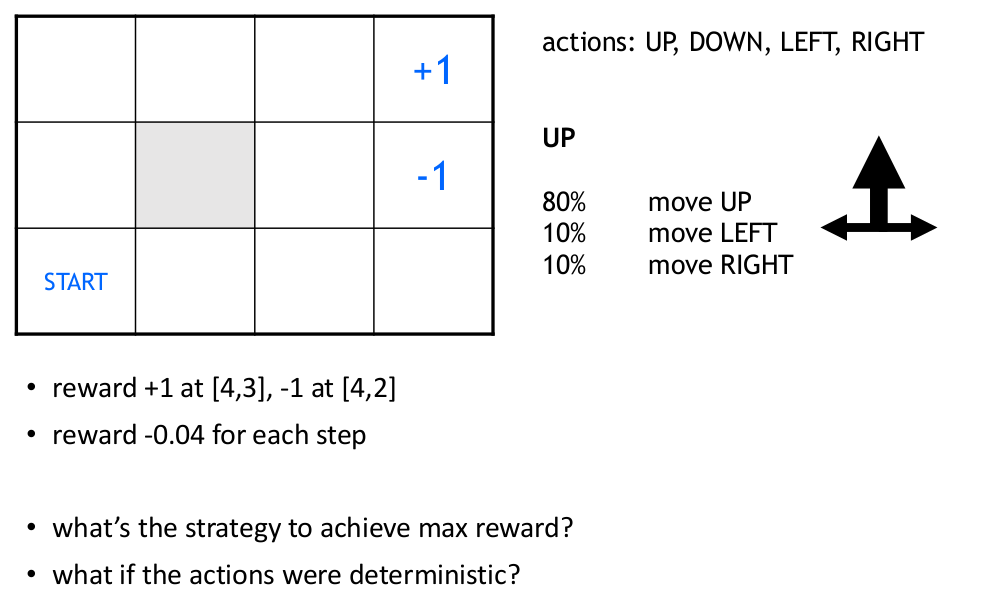
A good strategy for an agent would be to always choose an action that maximizes the (discounted) future reward
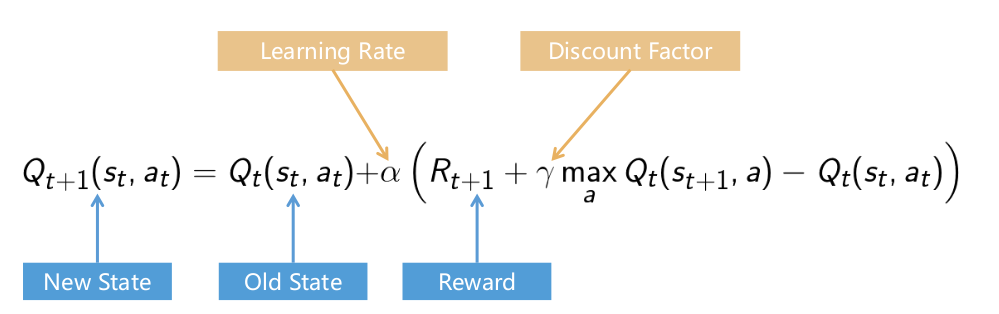
6 Q-Learning
Off-Policy Learning
- Use any policy to estimate Q that maximizes future reward
- Q directly approximates Q* (Bellman optimality equation)
- Independent of the policy being followed
- Only requirement: keep updating each (s,a) pair
6.1 Exploration vs Exploitation
- Key ingredient of Reinforcement Learning
- $$ \epsilon -greedy$$ policy
6.2 제약
In practice, Value Iteration is impractical
- Very limited states/actions
- Cannot generalize to unobserved states
7. Deep Reinforcement Learning
Philosophical Motivation for Deep Reinforcement Learning
- Takeaway from Supervised Learning: Neural networks are great at memorization and not (yet) great at reasoning.
- Hope for Reinforcement Learning: Brute-force propagation of outcomes to knowledge about states and actions. This is a kind of brute-force “reasoning”.
- Hope for Deep Learning + Reinforcement Learning: General purpose artificial intelligence through efficient generalizable learning of the optimal thing to do given a formalized set of actions and states (possibly huge).
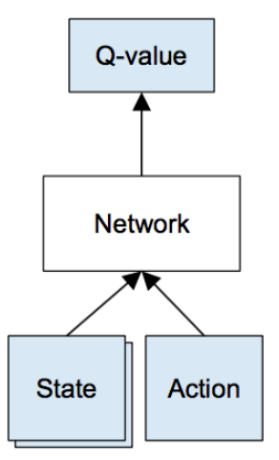
7.1 Deep Q-Network Training
Given a transition < s, a, r, s’ >, the Q-table update rule in the previous algorithm must be replaced with the following:
- Do a feedforward pass for the current state s to get predicted Q-values for all actions
- Do a feedforward pass for the next state s’ and calculate maximum overall network outputs max a’ Q(s’, a’)
- Set Q-value target for action to r + γmax a’ Q(s’, a’) (use the max calculated in step 2).
- For all other actions, set the Q-value target to the same as originally returned from step 1, making the error 0 for those outputs.
- Update the weights using backpropagation.
7.2 Exploration vs Exploitation
- Key ingredient of Reinforcement Learning
7.3 Experience replay
- ???
8. General Reinforcement Learning Architecture (Gorila)
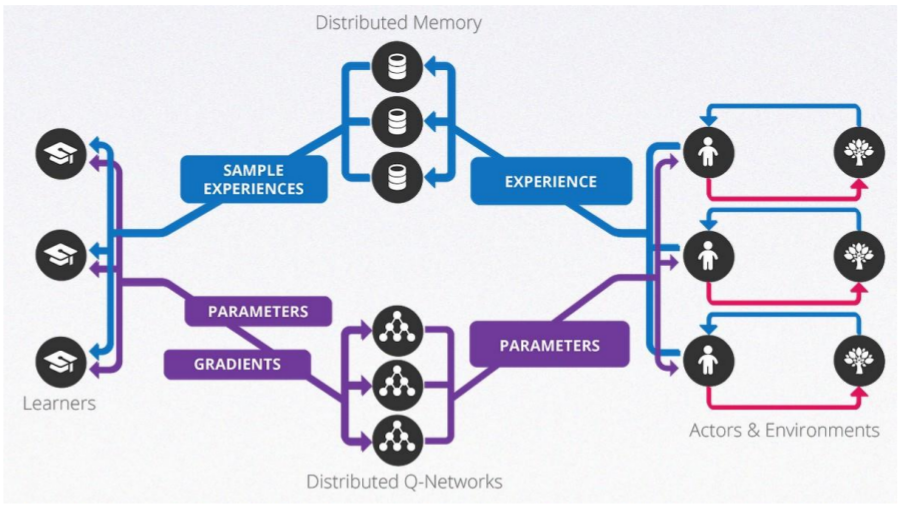
- 10x faster than Nature DQN on 38 out of 49 Atari games
- Applied to recommender systems within Google
Nair et al. "Massively parallel methods for deep reinforcement learning." (2015).
9. The Game of Traffic
Open Question (Again): Is driving closer to chess or to everyday conversation?
DeepTraffic: Solving Traffic with Deep Reinforcement Learning
- Goal: Achieve the highest average speed over a long period of time.
- Requirement for Students: Follow tutorial to achieve a speed of 65mph
Evaluation
- Scoring: Average Speed
Tutorial: http://cars.mit.edu/deeptraffic Simulation: http://cars.mit.edu/deeptrafficjs