Convolutional Neural Networks for End-to-End Learning of the Driving Task
1. 수업 내용
- CNN
- DeepTesla
- Tensorflow
2. Computer Vision
Images are Numbers
다루는 문제들
- Regression: The output variable takes continuous values(eg. 운전대 각도)
- Classification: The output variable takes class labels(eg. 고양이, 개 분류)
2.1 Computer Vision이 어려운 이유

2.2 K-Nearest Neighbor를 이용한 이미지 분류
2.3 CNN 이용한 학습
2.4 일반 NN와 CNN의 차이는?
3. Convolutional Neural Networks: Layers
- INPUT [32x32x3] will hold the raw pixel values of the image, in this case an image of width 32, height 32, and with three color channels R,G,B.
- CONV layer will compute the output of neurons that are connected to local regions in the input, each computing a dot product between their weights and a small region they are connected to in the input volume. This may result in volume such as [32x32x12] if we decided to use 12 filters.
- RELU layer will apply an elementwise activation function, such as the max(0,x) thresholding at zero. This leaves the size of the volume unchanged ([32x32x12]).
- POOL layer will perform a downsampling operation along the spatial dimensions (width, height), resulting in volume such as [16x16x12].
- FC (i.e. fully-connected) layer will compute the class scores, resulting in volume of size [1x1x10], where each of the 10 numbers correspond to a class score, such as among the 10 categories of CIFAR-10. As with ordinary Neural Networks and as the name implies, each neuron in this layer will be connected to all the numbers in the previous volume.
4. How Can Deeplearning(CNN) Help Us Drive?

4.1 Localization and Mapping: Where am I?
A. 활용 데이터
- Visual Odometry (영상 주행 기록기1)
B. Visual Odometry in Parts
- (Stereo) Undistortion, Rectification
- (Stereo) Disparity Map Computation
- Feature Detection (e.g., SIFT, FAST)
- Feature Tracking (e.g., KLT: Kanade-Lucas-Tomasi)
- Trajectory Estimation
- Use rigid parts of the scene (requires outlier/inlier detection)
- For mono, need more info* like camera orientation and height of off the ground
Kitt, Bernd Manfred, et al. "Monocular visual odometry using a planar road model to solve scale ambiguity." (2011).
SLAM: Simultaneous Localization and Mapping
C. End-to-End Visual Odometry
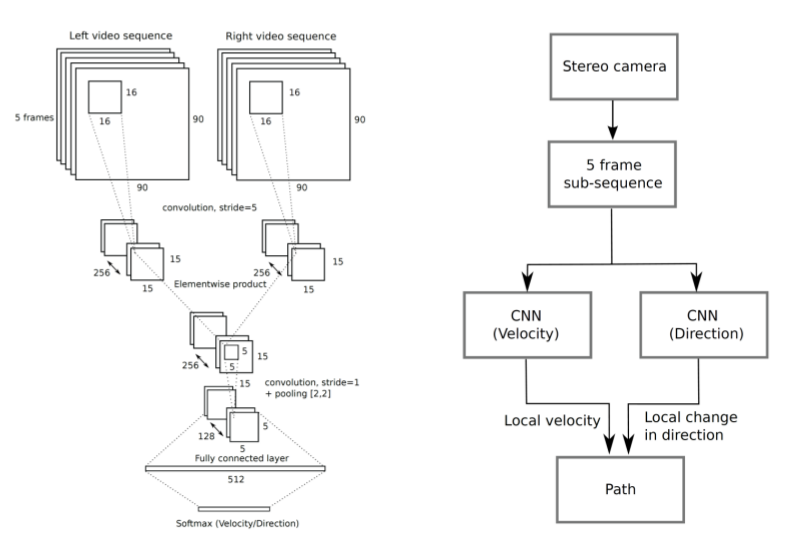
Konda, Kishore, and Roland Memisevic. "Learning visual odometry with a convolutional network." International Conference on Computer Vision Theory and Applications. 2015.
4.2 Scene Understanding: Where is everyone else?
딥러닝이 효과를 보이는 부분 : recognition, classification, detection
* 기존 방법 : cascades classifiers (Haar-like features)
A. Segmentation
B. Road Condition from Audio
- Road Texture and Condition from Audio
- RNN활용
4.3 Movement Planning: How do I get from A to B?
딥러닝이 효과를 보이는 부분 : Reinforcement Learning 활용
* 기존 방법 : optimization-based control
4.4 Driver State: What’s the driver up to?
Drive State Detection: Body Pose, Head Pose, Blink Rate, Blink Duration, Gaze Classification, Eye Pose, Drowsiness , Blink Dynamics, Micro Glances, Pupil Diameter,Micro Saccades, Cognitive Load
5.DeepTesla
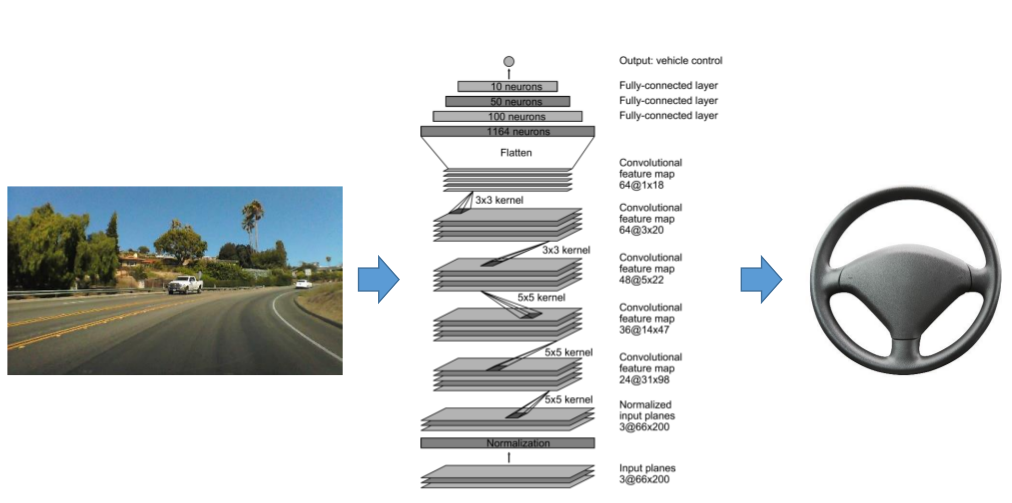
- 이미지(66x200 pixel)를 입력받아, 운전대 Value(-20~20 Degree) 보내기
- 9 layers
- 1 normalization layer
- 5 convolutional layers
- 3 fully connected layers
- 27 million connections
- 250 thousand parameters
데이터 살펴 보기
- 10개의 전방 카메라 운행 동영상
- 상하단 잘라서 운전석 이미지만 보이게 함
- CAN을 이용하여 Wheel value 수집
ConvNetJS – Training Overview
- To train a network, you first must initialize a “Trainer” object
var trainer = new convnetjs.SGDTrainer(net, { method: ‘adadelta’, batch_size: 1, l2_decay: 0.0001}); - There are three training algorithms available: SGD, Adadelta, and Adagrad.
- Training is performed by manually calling trainer.train(input_volume, expected_output)
Returns an object containing timing and loss function information
- GitHub: End-to-End Driving with TensorFlow :
- GitHub:별첨
ppt자료에 신호등 색상 파악하는 텐서플로우 코드 올려져 있음
[^1: CV 학계에서 잘 알려진 Logitech C920활용