딥러닝의 역사
- 1950년대 :뇌의 뉴런(단층)을 살펴 보니 간단(Wx+B)하고 이를 이용하여 AND / OR등(당시 중요 평가지표)의 문제 해결이 가능함 확인
- XOR도 중요한 지표인데 기존(단층)뉴런으로는 해결 할수 없다.
- 암흑기
- 1969년 : 다층 뉴런을 사용하면 XOR도 해결 가능하다 by Minsky, MIT
- 단, 다층 뉴런간의 W,B학습이 불가능 하다.
- No one on the earth had found a viable way to train
- 10~20년 1차 암흑기
- 1974,1982년 : W,B학습은 Backpropagation 알고리즘 통해 해결 가능 by Paul Werbos
- 1986년 Hilton교수에 의하여 재발견 및 알려짐
- 1980년 후반 : CNN알고리즘은 5개층까지도 학습이 가능 하여 이미지 인식에 큰 발전 가능
- Yann LeCun은 CNN에 역전파를 적용하여 필기 인식에 응용
- 1995년 Backpropagation은 2~3개의 레이어는 가능하지만, 깊은 층에서는 학습이 잘 되지 않음, 오버피팅 문제 존재
- SVM, RF가 더 좋은 결과 보임
- Vanishing Gradient
- 2차 암흑기 (1986-2006)
- 2006년 깊은층의 학습을 위해서 아래의 내용들을 해결 하면 가능하다. by hilton, Bengio
- Our labeled datasets ware thousands of times too small
- Our computers were million of times too slow
- We initialized the weight in a stupid way (RBM, DBN, 오토인코더)
- We used the wrong type of non-Linearity (Sigmoid -> Relu로 해결)
Deep Learning으로 재 명명 (뉴럴넷이 부정적 이미지가 많음)
- 2012년 ImageNet 경연대회에서 딥러닝기반 AlexNet으로 26.2% -> 15,3%로 떨어트림 by Hilton교수랩 Alex박사 과정
- 2015년 인간에러 5% 보다 좋은 성능 보임
CNN은 일반적으로 Pre-Training(DBN, 오토인코더)절차를 사용하지 않음
AI Winter
- 1974~1980
- 1987-1993
기초학습
1. Prediction
1-1 One Variable(리니어) Regression
- Hypothesis : 데이터에 잘 맞는 직선은 무엇인가?
- $$H(x) = wx+b$$
- cost(loss) 함수 : 가설이 실제값에 얼마나 맞는가 검사
- (가설값-실제값)의 제곱의 합 평균
- 목적 : Cost함수를 최소화 하는 w,b 찾기
Gradient Decent
- Minimize Cost Function
- W 값에 따른 Cost(w) 그래프를 그리고 최소 값 찾기
- 최소값 찾는 방법 = W,b값을 조금씩 바꾸어 가면서 경사도(=기울기)를 기반으로 0에 가까운값 찾기
- 경사도 구하는 법 = 미분 활용
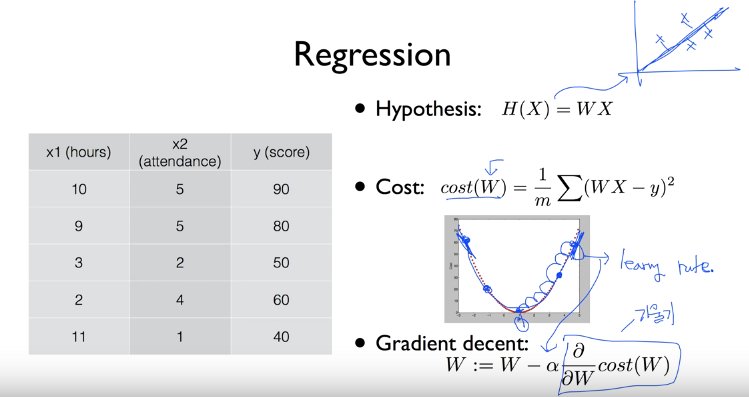
- x = W, y = Cost(w)
$$ \alpha $$ = Learning rate, 기울기를 찾아 내려 갈때 이동거리(발자국)
$$ \frac{\partial}{\partial W} cost(w) $$ : 코스트 함수를 미분
1-2 Multi Variable Regression
- Hypthesis : 변수 수만 변함
- $$H(x_1,x_2,x_3) = w_1x_1 + w_2x_2 + w_3x_2 +b $$
- cost(loss) 함수 : 변화 없음
Variable이 많을 경우 계산시 Matrix(행렬)연산 사용


- Bias를 행렬에 포함시키기 위해 w의 앞에 b를 x의 위에 1을 입력
2. Classification
2-1 Bi-Classification : Logistic Regression
- 딥러닝에 많이 사용되므로 중요
- 실수를 On or Off로 구분 하기 위해서
- Hypothesis : 리니어 H + 시그모이드 G 혼합
- $$ H(x) = \frac{1}{1+e^-WX} $$
혼합이유 : 0~1의 값을 내어야 함 = 시그모이드(=로지스틱)함수 이용 하여 가능 = $$ g(x) = \frac{1}{1+e^-z} $$
- cost(loss) 함수 수식 설명 https://youtu.be/6vzchGYEJBc?t=4m48s
2-2 Multi-classification : Softmax Classification
- 여러 로지스틱을 가지고도 구현 가능하지만 추가 기능 필요
- eg. A,B,C학점 = A or Not, B or Not, C or Not
 2.0 / 1.0 / 0.1의 결과가 아니라 총합이 1인 확률값(0.7/0.2/0.1)으로 나오게 하는것
2.0 / 1.0 / 0.1의 결과가 아니라 총합이 1인 확률값(0.7/0.2/0.1)으로 나오게 하는것
one-hot Encoding을 이용하면 가장 큰값만 선택하고 나머지는 0으로 선택(argmaxg함수 사용)
- cost(loss) 함수 : Cross-Entropy
- Cost 함수(Cross Entropy)설명 :Youtube
정의
- 미분 : 미세한게 나누다
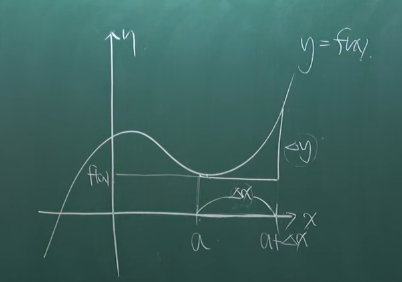
- 변화량과 변화량을 나누다 $$ \frac{\Delta y}{\Delta x} $$
- 미세하게 나눈다 = $$ \Delta x \rightarrow 0$$으로 보낸다 =x의 변화량을 0처럼 미세하게 한계치($$\lim_{\Delta x \rightarrow 0}$$)까지로 만든다.
$$ \lim_{h \rightarrow 0}\frac{\Delta y}{\Delta x} = 변화량과 변화량을 미세하게 나누어서 값을 구한다.
$$
- 결국, 접선의 기울기(=순간변화율=미분 계수)
- x에 대한 기울기값f(x) 출력 - 함수역할 - 도함수라 부름
- cf. 평균변화율 = 직선의 기울기
공식 유도
$$ 원 공식 \frac{f(b)-f(a)}{b-a} 에서 $$
$$ b는 a에서 \Delta x만큼 이동한 것이므로 b= a+\Delta x로 치환 $$
$$ 즉, \frac{f(a+\Delta x)-f(a)}{a+\Delta x-a} = \frac{f(a+\Delta x)-f(a)}{\Delta x} $$
표현의 간결성을 위해 $$ \Delta x$$를 $$h$$로 치환 = $$\frac{f(a+h)-f(a)}{h} $$
표기법 1
- $$ \Delta x$$는 x의 변화, 미세한 x의 변화량 $$dx$$ 로 표시(d=differentiation)
- $$ \frac{dy}{dx} $$ =
y라는 함수를 x를 변수로 해서 미분하시오
표기법 2
$$ f^\prime (a) $$ = a에서 f의 미분값, 도함수
미분이라는 행위를 했을 때 나온 식이 도함수고
이를 함수라 표현한 이유가 어떤 값하나에 다른 하나의 식이 나오니까 도함수(x를 넣으면 그때의 미분계수/기울기를 알수 있는)라 칭함
표기법 3
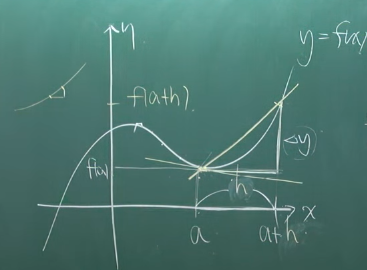
- $$\Delta x$$를 $$h$$로 치환
- $$x$$의 변화량 $$h$$, 이때 $$y$$의 변화량은 $$ f(a+h) $$
$$ 즉, \frac{dy}{dx} = f^\prime (a) = \lim_{h \rightarrow 0} \frac{f(a+h)-f(a)}{h}
$$
결국 : $$ f^\prime (a) = y^\prime = \frac{d}{dx}y = \frac{d}{dx}f(x) $$
미분을 나타내는 방법
$$ \lim_{h \rightarrow 0}\frac{A-B}{C} : A에서 B를 뺀게 C에 있게되면 미분을 나타내는 것임
$$
식 1
$$ \lim_{h \rightarrow 0}\frac{f(x+h)-f(x)}{h} = \frac{f(x)-f(x+h)}{-h}
$$
식2
$$ \lim_{h \rightarrow a}\frac{f(x)-f(a)}{x-a} = \frac{f(a)-f(x)}{a-x}
$$
미분과 기울기
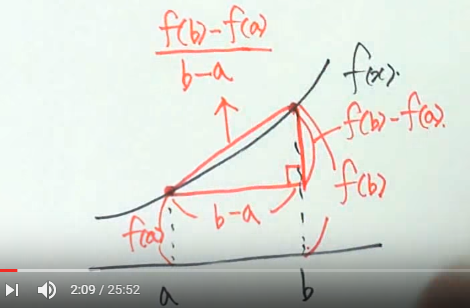
기울기 $$= \frac{높이}{밑변의 변화량} = \frac{f(b)-f(a)}{b-a} = \frac{\Delta y}{\Delta x}$$
b-a : x의 증가량
f(b)-f(a) : y의 증가량
식 1과는 일치
식 2도 풀어 쓰면 아래와 같으므로 일치
$$ \lim_{h \rightarrow 0}\frac{f(x+h)-f(x)}{h} = \frac{f(x)-f(x+h)}{-h} = \frac{f(x+h)-f(x)}{(x+h)-(x)}
$$

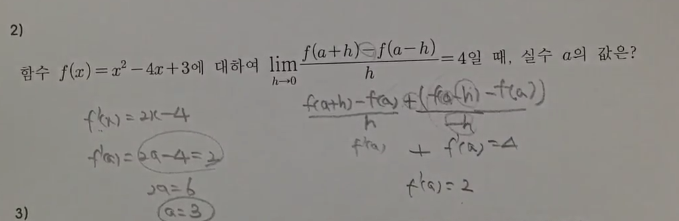
뉴럴네트워크를 이해하는데 필요한 미분

- 상수를 미분하면
0 - f(x)=x 를 미분하면,
1이되고, 앞에 상수는 그대($$x*1$$)로 따라 붙는다
Partial Derivative

- 내가 관심(미분)있는것은 제외하고 나머지는 상수로 둔다
- $$ f(x,y) = xy, \frac{\partial f}{\partial x} = y $$ ( x는 미분 대상, y는 상수 )
Chain rule
- $$f(g(x)) = \frac{\partial f}{\partial g}*\frac{\partial g}{\partial x} $$
- 복잡한 형태는 각각을 곱하면 된다
참고