RNN (Recurrent Neural Networks)
출처
1. 기본 개념
RNNs의 목적은 배열 (시계열) 데이터를 분류하는 것이라고 말씀드렸습니다. 그리고 RNNs의 학습은 다른 인공 신경망의 학습과 마찬가지로 오차의 backprop과 경사 하강법(Gradient Descent)을 사용합니다.
- Sequence Data 처리 (eg. 음성)
- 현재의 데이터가 과거의 데이터의 영향을 받는다.
- NN/CNN은 Sequence를 처리 못함
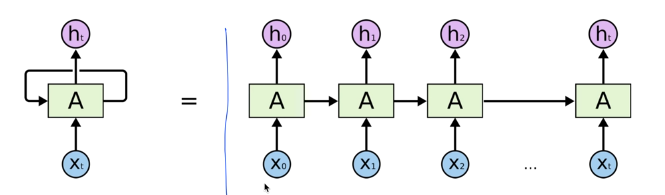
RNNs은 backprop의 확장판인 BTPP(Backpropagation Through Time)을 사용해 계수를 학습합니다.
- 본질적으로 BTPP는 기본적인 backprop과 똑같습니다.
- 다만 RNNs의 구조가 시간에 따라 연결되어 있기 때문에 backprop역시 시간을 거슬러 올라가며 적용되는 것 뿐입니다.
2. RNN 종류
2.1 Vanilla RNN

$$ ht = \tanh(W(h{t-1}, x_t)+b) $$
- $$h$$ = 현재의 은닉 상태
- $$x$$ = 현재의 입력
2.2 LSTM(Long short term memory)

RNNs의 변형인 LSTM(Long Short-Term Memory) 유닛은 90년대 중반에 처음으로 등장했습니다.
LSTM은 오차의 그라디언트가 시간을 거슬러서 잘 흘러갈 수 있도록 도와줍니다
- Vanilla RNN도 깊어 지면 학습이 어려워 짐으로 최근에는 LSTM 을 많이 사용
셀상태라는 새로운 연산값 필요
- 하나의 컨베이어 벨트 같이 전체 체인을 관통 - 큰 변화없이 정보 유지가 가능
게이트라는 요소를 이용하여 정보를 더하거나 제거 함
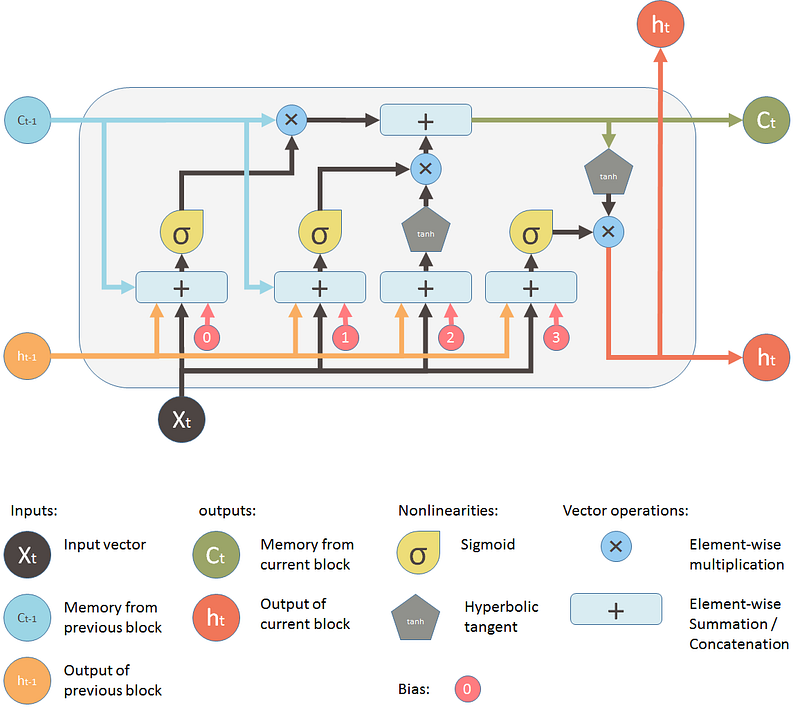
A. 삭제 게이트/Forget gate layer$$(f_t)$$

- 이전 셀 상태 값중에서 삭제해야 하는 정보를 학습하기 위한 게이트
시그모이드($$\sigma$$)레이어로 만들어짐- $$ h_{t-1} 과 x_t$$를 입력으로 받아 시그모이드 출력값이 1이면 유지, 0이면 버림
B. 입력 게이트$$(i_t)$$

새로운 정보가 셀 스테이트에 저장 될지를 결정하는 게이트
Step 1: Sigmoid Layer를 이용하여 어떤 값을 업데이트 할지 결정
- Step 2: Tanh Layer를 새로운 후보값을 만들어 냄
C. 셀 상태 업데이트

- $$ C_{t-1}$$ 가 삭제 게이트 + 입력 게이트를 지나면서 $$ C_t $$로 업데이트
D. 출력 게이트 / 최종 출력값 결정
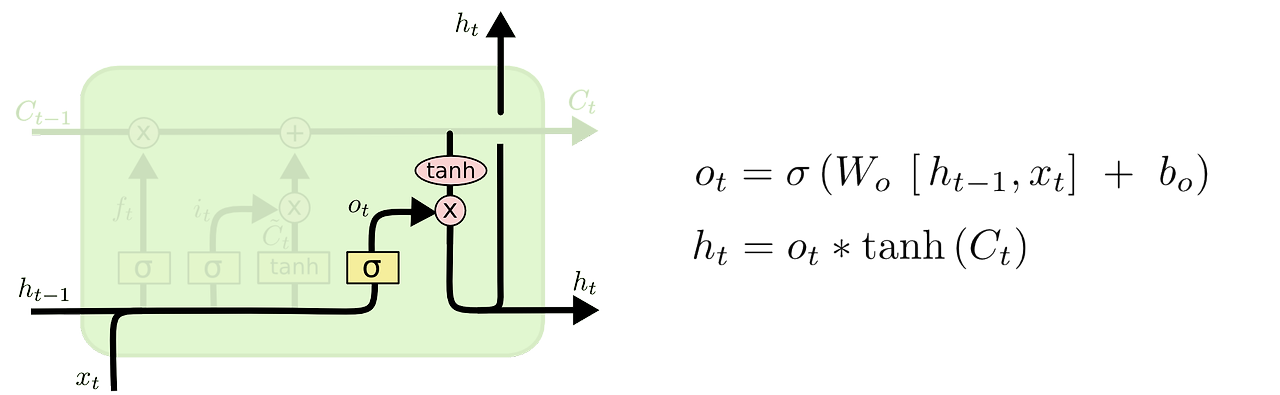
- 필터링된 셀 상태 값
정리

$$ ft = C{t-1} \times sigmoid(p_t) $$
- C = 셀상태 ($$ f_t + i_t $$)
- $$ p = W(h_{t-1}, x_t)+b $$
$$ i_t = sigmoid(p_i) \times tanh(p_j) $$
$$ h_t(은닉상태) = tanh(c_t) \times sigmoid(p_o) $$
3. RNN Regularizations (오버피팅 문제)
3.1

드랍 아웃 기법 적용
- 순환 신경망의 출력 값의 흐름 중
수직방향에 대해서만 드랍아웃을 적용 - [조심] 순환되는 데이터에는 드랍아웃을 적용하지 않음
3.2
추천 : 꼭 읽어 보기
4. 응용
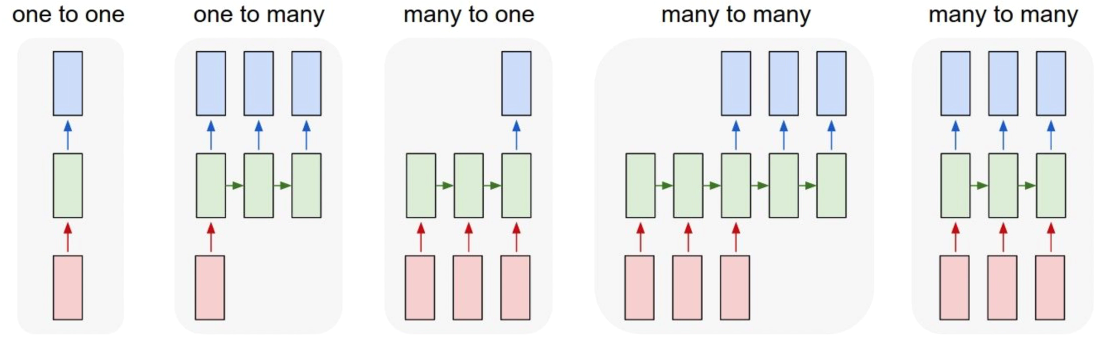
- One-to-One : Vanilla Neural Networks
- One-to-Many : Image Captioning (Image -> Sequence of words)
- Many-to-One : Sentiment Classification (Sequence of words -> Sentiment)
- Many-to-Many : Machine Translation (Seq of words -> seq of words)
- Many-to-many : Video Classification on frame level
[Tip] LSTM 하이퍼파라미터 정하기
LSTM의 하이퍼파라미터를 정하는 팁을 몇 가지 적어놓았으니 참고하십시오.
- 과적합(overfitting)이 일어나는지를 계속 모니터링하십시오. 과적합은 신경망이 학습 데이터를 보고 패턴을 인식하는 것이 아니라 그냥 데이터를 외워버리는 것인데 이렇게 되면 처음 보는 데이터가 왔을 때 제대로 결과를 내지 못합니다.
- 학습 과정에서 규제(regularization)가 필요할 수도 있습니다. l1-규제, l2-규제, 드롭아웃을 고려해보십시오.
- 학습엔 사용하지 않는 시험 데이터(test set)를 별도로 마련해두십시오.
- 신경망이 커질수록 더 많고 복잡한 패턴을 인식할 수 있습니다. 그렇지만 신경망의 크기를 키우면 신경망의 파라미터의 수가 늘어나게 되고 결과적으로 과적합이 일어날 수 있습니다. 예를 들어 10,000개의 데이터로 수백만개의 파라미터를 학습하는 것은 무리입니다.
- 데이터는 많으면 많을수록 좋습니다.
- 같은 데이터로 여러 번 학습을 시켜야합니다.
- 조기 종료(early stopping)을 활용하십시오. 검증 데이터(validation set)를 대상으로 얼마나 성능이 나오는지 확인하면서 언제 학습을 끝낼 것인지를 정하십시오.
- 학습 속도(running rate)를 잘 설정하는 것은 정말 너무너무 중요합니다. DL4J의 ui를 써서 학습 속도를 조절해보십시오. 이 그래프를 참고하십시오.
- 다른 문제가 없다면 레이어는 많을수록 좋습니다.
- LSTM에서는 하이퍼탄젠트보다 softsign함수를 사용해보십시오. 속도도 더 빠르고 그라디언트가 평평해지는 문제(그라디언트 소실)도 덜 발생합니다.
- RMSProp, AdaGrad, Nesterove’s momentum을 적용해보십시오. Nesterove’s momentum에서 시작해서 다른 방법을 적용해보십시오.
- 회귀 작업에서는 데이터를 꼭 정규화하십시오. 정말 중요합니다. 또, 평균제곱오차(MSE)를 목적 함수로 하고 출력층의 활성함수(activation function)은 y=x(identity function)을 사용하십시오. (역자 주: 회귀 작업이라도 출력값의 범위를 [0,1]로 제한할 수 있다면 binary cross-entropy를 목적 함수로 사용하고 출력층의 활성함수는 sigmoid를 사용하십시오.)

import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
mnist = input_data.read_data_sets("./mnist_data", one_hot=True)
learning_rate = 0.001
training_iters = 100000
batch_size = 128
display_step = 10
n_input = 28
n_steps = 28
n_hidden = 128
n_classes = 10
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
weights = tf.Variable(tf.random_normal([n_hidden, n_classes]))
biases = tf.Variable(tf.random_normal([n_classes]))
x_trans = tf.transpose(x, [1, 0, 2])
x_reshape = tf.reshape(x_trans, [-1, n_input])
x_input = tf.split(0, n_steps, x_reshape)
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell( n_hidden, forget_bias=1.0)
outputs, states = tf.nn.rnn(lstm_cell, x_input, dtype=tf.float32)
pred = tf.matmul(outputs[-1], weights) + biases
cost = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(pred, y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
step = 1
while step * batch_size < training_iters:
batch_x, batch_y = mnist.train.next_batch(batch_size)
batch_x = batch_x.reshape((batch_size, n_steps, n_input))
feed_dict = {x: batch_x, y: batch_y}
sess.run(optimizer, feed_dict)
if step & display_step == 0:
acc = sess.run(accuracy, feed_dict)
loss = sess.run(cost, feed_dict)
print "Iter " + str(step*batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + ", Training Accuracy= " + "{:.5f}".format(acc)
step += 1
print "Optimization Finished!"
test_len = 128
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print "Testing Accuracy:", sess.run(accuracy, feed_dict)
텐서플로로 구현된 LSTM 쉬운 예제입니다. 간단한 사용법만 잘 숙지하면 이렇게 간단하게 구현할 수 있네요.
이걸 못해서 여태 계속 어려운 코드만 눈빠져라 보고 있었던 시간이 허무해집니다 ㅠㅠ
MNIST 이미지에서 하나의 row를 하나의 데이터로 보고 한 이미지에 들어있는 row들의 집합을 시퀀스로 해석해서 풉니다.
mnist 데이터 28by28이니까 28개의 row가 나오는 것이고 28개의 row 데이터들의 하나의 숫자를 의미하는 시퀀스가 되겠습니다. 그런 식으로 해서 mnist 손글씨 인식을 해내는 코드입니다.
출처 : 모두의 연구소
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
learning_rate = 0.001
training_iters = 100000
batch_size = 128
display_step = 10
n_input = 28
n_steps = 28
n_hidden = 128
n_classes = 10
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
weights = tf.Variable(tf.random_normal([n_hidden, n_classes]))
biases = tf.Variable(tf.random_normal([n_classes]))
x = tf.transpose(x, [1, 0, 2])
x = tf.reshpae(x, [-1, n_input])
x = tf.split(0, n_steps, x )
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell( n_hidden, forget_bias=1.0)
outputs, states = tf.nn.rnn(lstm_cell, x, dtype=tf.float32)
pred = tf.matmul(outputs[-1], weights ) + biases
cost = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(pred, y))
train = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
step = 1
while step * batch_size < training_iters:
batch_x, batch_y = mnist.train.next_batch(batch_size)
batch_x = batch_x.reshape((batch_size, n_steps, n_input))
sess.run(train, feed_dict={x: batch_x, y: batch_y})
if step % display_step == 0:
acc = sess.run(accuracy, feed_dict={x: batch_x, y: batch_y})
loss = sess.run(cost, feed_dict={x: batch_x, y: batch_y})
print "step : %d, acc: %f" % ( step, acc )
step += 1
print "train complete!"
test_len = 128
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print "test accuracy: ", sess.run( accuracy, feed_dict={x: test_data, y: test_label})