Activation Function
0. 개요
0.1 역사
1957년에 Rosenbalt는 “Perceptron”이라는 용어 및 개념을 발표 : Step function(계단함수)
- 단점, Weigth 학습을 위해 역전파시 미세한 변화에도 출력층에 변화를 만들어 내야 하는데 계단함수는 0,1 극단적인 결과라 미세한 변화에 반응이 없음
- 해결책 : 연속적 출력값을 가지도록 함
- ‘linear’ : 디폴트 값, 입력뉴런과 가중치로 계산된 결과값이 그대로 출력으로 나옵니다.
- ‘relu’ : rectifier 함수, 은익층에 주로 쓰입니다.
- ‘sigmoid’ : 시그모이드 함수, 이진 분류 문제에서 출력층에 주로 쓰입니다.
- ‘softmax’ : 소프트맥스 함수, 다중 클래스 분류 문제에서 출력층에 주로 쓰입니다.
0.2 활용
- 일반적으로 단조증가(Monotone increasing)하는 비선형함수가 사용됨다.
- 하지만, 목적에 따라서 선형 사상을 사용 하기도 함
- 회귀 문제 = 항등사상
- 분류 문제 = 소프트맥스
활성화 함수로 선형 함수를 사용 하면 안되는가? 은닉층의 효과가 없어 지므로 사용 하면 안됨
[참고] DIFFERENCE BETWEEN SOFTMAX FUNCTION AND SIGMOID FUNCTION
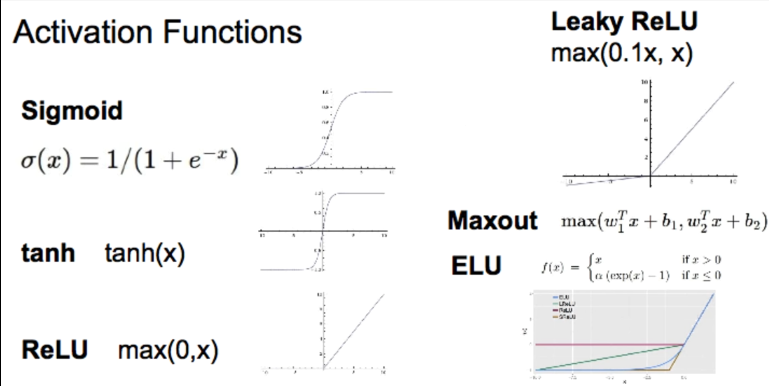
1. Sigmoid 함수
- Logistic sigmoid function = Logistic function
$$ \sigma(z) \equiv \frac{1}{1+e^{-z}}
$$
- z는 각각의 입력(x1, x2, x3, …)과 가중치(w1, w2, w3, ..)를 곱한 값에 bias를 더한 값
단점
Vanishing gradient문제 발생: Deep-wide 네트워크에서 Back propagation할경우 sigmoid의 0~1의 문제로 제대로 Input Layer까지 전달 안됨 [Youtube 추가설명]
너무 커질경우 0이나 1이 되어 버림
해결책 : sigmoid 함수를 개선한 tanh(탄젠트) 함수 사용, 최종 산출이 임의의 실수 ($$ [-1:1] $$)를 가지는 경우
2. ReLu(Rectified Linear Unit)
sigmoid , tanh은 느린 학습 속도 문제 해결. 약 6배 속도 향상
램프(ramp function, rectified linear function)를 이용
0보다 작으면 off, 0보다 크면 계속 증가 (ReLu)
단순하지만, 계산량이 적으며 학습이 빠르고 결과도 좋음
ReLu를 사용하더라라도 구현시 마지막 레이어에서는 0~1사이의 값이어야 하므로 Sigmoid 사용
램프함수와 관계 깊은 MaxOut이란 함수가 있음. CNN에서
최대풀링과 비슷
3. Leaky ReLu
- O보다 작으면 Off하지 말고, 작은 폭의 -를 가지게 하자
- Max(0.1x, x)
5. 항등사상(Identity mapping)
- 회귀문제를 위한 신경망에서는 출력층으로 항등사상 사용
최종 산출이 임의의 실수 ($$ -\infty ~ \infty $$)를 가지는 경우
6. 선형사상(Linear mapping)
7. 소프트 맥스
- 클래스 분류를 목적으로 하는 신경망에서는 출력층으로 소프트맥스 함수 사용
- logistic regression이라고도 불린다
7.1 수식
$$ \sigma(z)j = \frac{e^{\approx j}}{\sum^{k}{k=1}e^{\approx k}} ... for j = 1,...,k
$$
- K-차원을 갖는 벡터 z를 (0,1) 범위를 갖는 σ(z)로 치환시키는 것
- Zk에 대해 편미분을 실시하면, j = k 일 때는 양수이고, j ≠ k 일 때는 음수가 된다.
- 즉, Zk를 증가시키면 해당 뉴런의 출력값 σ(z)는 증가하고, 다른 뉴런의 출력값은 감소하게 되는 성질을 갖게 된다.
Softmax 미분 유도 공식들
7.2 특징
- 소프트맥스는 입력값을 지수화한 뒤 정규화(=합이 1이므로) 하는 과정 [설명]
- 지수화란 증거값을 하나 더 추가하면 어떤 가설에 대해 주어진 가중치를 곱으로 증가시키는 것을 의미합니다. 또한 반대로, 증거값의 갯수가 하나 줄어든다는 것은 가설의 가중치가 기존 가중치의 분수비로 줄어들게 된다는 뜻입니다.
- 어떤 가설도 0 또는 음의 가중치를 가질 수 없습니다.
- 그런 뒤 소프트맥스는 가중치를 정규화한 후, 모두 합하면 1이 되는 확률 분포로 만듭니다 참고
[참고] Sigmoid Vs. Softmax
- Sigmoid : 해당 뉴런으로 들어오는 입력 & 바이어스에 의해 출력이 결정되는 구조
- Softmax : Sigmoid 구조 + 다른 뉴런의 출력값과의 상대적인 비교 (합이 1이되게) = non-locality라고 부름
최근 트랜드 함수
SNN(Self-Normalizations Neural Networks):논문 ,구현#1, 구현#2
- 배치 normalization은 명확한 normalization을 필요로하지만 SNNs는 저절로 0으로 수렴해 간다고 하는데, 이를 위해 도입한 것이 SELUs(scaled exponential linear units) 입니다
What is the Role of the Activation Function in a Neural Network?