Overfitting 문제 해결법
# 다른 분류
1. Feature Normalization
2. Regularization : Loss에 Term 추가
3. More Data (Augmentation)
4. Drop Out
5. Batch Normalization
```
More Training data
Reduce the number of feature : PCA
Regularization (정규화,일반화)
- Weight : error 함수 또는 cost 함수를 변형하여 penalty를 활용하는 방안
- Dropout : 망 자체를 변화(부분 생략)하는 방안
- Local Response Normalization(LRN)
- Batch Normalization(BN)
- Early Stopping
- Reduce Network Size
1. More Training data = Image augmentation
| Affine Transform | Elastic Distortion |
|---|---|
 |
 |
| Affine Transform의 4가지 연산 이용 | 다양한 방향으로의 displacement vector를 만들어내고 그것을 통해 좀 더 복잡한 형태의 훈련 데이터 생성 |
2. Reduce the number of feature
3. Regularization
3.1 Weight Decay(가중치 감쇠)
L2 Regularization
$$ C = C_0 + \frac{\lambda}{2n}\sum_w w^2
$$
- C: 원래의 Cost 함수
- n: 훈력 개수
- $$\lambda$$: regularization 변수, 규제화의 강도, 0.01 ~0.00001 범위
- w : 가중치
새 Cost 함수의 목적
- 학습시 w에 대한 자유도 제약(w 값들 역시 최소가 되는 방향으로 진행)
- w가 작아지도록 학습 = “local noise”가 학습에 큰 영향을 끼치지 않는다는 것
- weight에 너무 큰값 주지 않기 (큰값 = 구부려짐 커짐)
- 결과적으로 가중치는 자신의 크기에 비례하는 속도롤 항상 감쇠
- Weight Decay는 신경망의 가중치w에만 작용하며, 바이어스b에는 적용하지 않는다.
[참고] L1 Regularization
L1 regularization은 2차항 대신에 1차항 사용
$$ C = C_0 + \frac{\lambda}{n}\sum_w \mid w\mid
$$
방법 : weight 값 자체를 줄이는 것이 아니라, w의 부호에 따라 상수 값을 빼주는 방식으로 regularization을 수행한다.
특징 : 작은 가중치들은 거의 0으로 수렴이 되어, 몇 개의 중요한 가중치들만 남게 된다
장점 : “sparse model(coding)”에 적합
단점 : 미분이 불가능한 점이 있기 때문에 gradient-based learning에 적용할 때는 주의가 필요하다.
[참고] 가중치 상한
- 가중치 값의 상한을 통해 가중치를 제약하는 방법
- 가중치 감쇠보다 나은 성능 보임
- Dropout 과 같이 사용 가능
3.2 Dropout
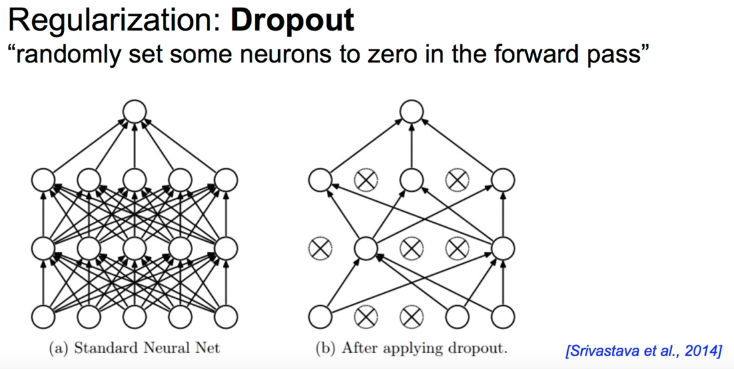
- 네트워크의 일부만 사용하여서 학습[1]
- (조심) Training 시에만 dropout_rate를
~0.9미만으로 적용하고, Evaluation 할때는 dropout_rate를1로 적용
신경망의 일부를 학습 시에 랜덤으로 무효화 하는 유사 방법(트롭커넥트, 확률적 최대 풀링)들이 존재 하나, 사용 편의와 적용 범위로 볼때 DropOut이 효과적
A. Voting 효과
Dropout을 하는 첫 번째 이유는 투표(voting) 효과 때문이다.
일정한 mini-batch 구간 동안 줄어든 망을 이용해 학습을 하게 되면, 그 망은 그 망 나름대로 overfitting이 되며, 다른 mini-batch 구간 동안 다른 망에 대해 학습을 하게 되면,그 망에 대해 다시 일정 정도 overfitting이 된다.
이런 과정을 무작위로 반복을 하게 되면, voting에 의한 평균 효과를 얻을 수 있기 때문에,결과적으로 regularization과 비슷한 효과를 얻을 수 있게 되는 것이다.
B. Co-adaptation을 피하는 효과
특정 뉴런의 바이어스나 가중치가 큰 값을 갖게 되면 그것의 영향이 커지면서 다른 뉴런들의 학습 속도가 느려지거나 학습이 제대로 진행이 되지 못하는 경우가 있다.
하지만 dropout을 하면서 학습을 하게 되면, 결과적으로 어떤 뉴런의 가중치나 바이어스가 특정 뉴런의 영향을 받지 않기 때문에 결과적으로 뉴런들이 서도 동조화(co-adaptation)이 되는 것을 피할 수 있다.
3.3 Local Response Normalization(LRN)
원시인 산수를 생각해 보자. 그들은 숫자를 셀때... 하나, 둘, 많다.로 셈을 한다. 이런 현상이 Neural Network에서도 발생한다. 아래의 두개의 list집합을 보자. [ 1, 3, -1, 2, 4, 6] [ 1343441, 45233233, -2323451, 3435342, 323344, 343446] 왼쪽의 list는 뭔가를 표현하고 있다는 느낌(?)이 온다. 그런데, 오른쪽은 그냥 큰 숫자들의 모임이라는 것외에 뭔가를 표현한다는 생각이... 즉, 감각신경에서 역치 이상의 자극이 주어지면 오히려 자극을 구분하지 못하게 되는 현상이 발생한다. 40도는 따듯하다고 느낄수 있지만, 10000도는 느끼지 못하는 것과 같다. 그래서 이들을 감각이 기능할 수 있는 숫자 영역으로 조정해 주는 것이 필요하다. 두번째 list를 적당히(표준편차) 나누고, 특정값을 빼주면(평균) 왼쪽 값처럼 만들수 있다. 이게 LRN의 역할이다.
ReLU는 포화를 막기 위한 입력 정규화를 필요로 하지 않음. 그러나, ReLU 다음에 적용되는 지역 정규화 방식(LRN)이 일반화를 도움, 결과적으로 인접한 커널들에 걸쳐 정규화됨

3.4 Batch Normalization(BN)
영어 공부열심히 하고 있다가, 갑자기 수학문제를 풀라고 하면 뇌가 좀 당황스럽다. 이러한 문제가 Network에도 발생한다. 학습하는 순서를 살펴보면... Layer에서 현재 설정된 weight(수학교재)로 열심히 계산(수학공부)을 해서, 다음 layer로 결과(수학답안) 넘겨준다. (forward) 조금 있으면 다음layer에서 미분값을 계산하고, 그걸 현재 layer가 (채점결과) 넘겨 받는다. backward로 넘겨받은 값을 이용해서 현재weight(kernel)을 update한다.
아~~~ 그런데, 문제가 생겼다. 이전에 weight(수학교재)를 update를 하고 나서 보니, 이게 영어교재가 되어버렸네? 다음에 update하면 국어 문제가 될수도 있겠네?
이렇게 공부하면 성적이 오를리가 없다. 한과목에 집중해야 한다. 즉, 현재의 출력을 어느 한과목으로 고정시켜주어야 한다. 이렇게 하면 현재 교재를 수학 -> 영어 -> 수학 -> 영어 -> 수학 -> 수학 -> 수학 -> 수학 ..... 으로 만들수 있다. 즉, kernel의 학습방향이 흔들리지 않도록 잡아주는 역할을 한다. 그래서, 수렴속도가 무지 빨라진다. 또, performance도 좋아진다.
출처 : SoyNature
[참고] 앙상블 & 드랍아웃 비슷한점
- 여러 학습 모델을 생성하고 마지막에 합쳐서 결과를 산출
- 2~4,5%까지 성능 향상 가능
- 충분한 컴퓨팅 파워 필요
[1]: Srivastava et al., "A Simple way to Prevent Neural Networks from Overfitting", 2014