Sensor Fusion — Part 2: Kalman Filter Code
이론 설명은 : Article - Kalman Filter basics 참고 (Sensor Fusion — Part 1: Kalman Filter basics)
깃허브 : Kalman Filter.py, 샘플파일.txt
Udacity’s github 데이터 활용 실습 (obj_pose-laser-radar-synthetic-input.txt)
- 해당 데이터에는 Lidar + radar이지만 본 실습은 lidar만 활용
- 추후 exKalman filter다룬시 Lidar+radar 실습 진행
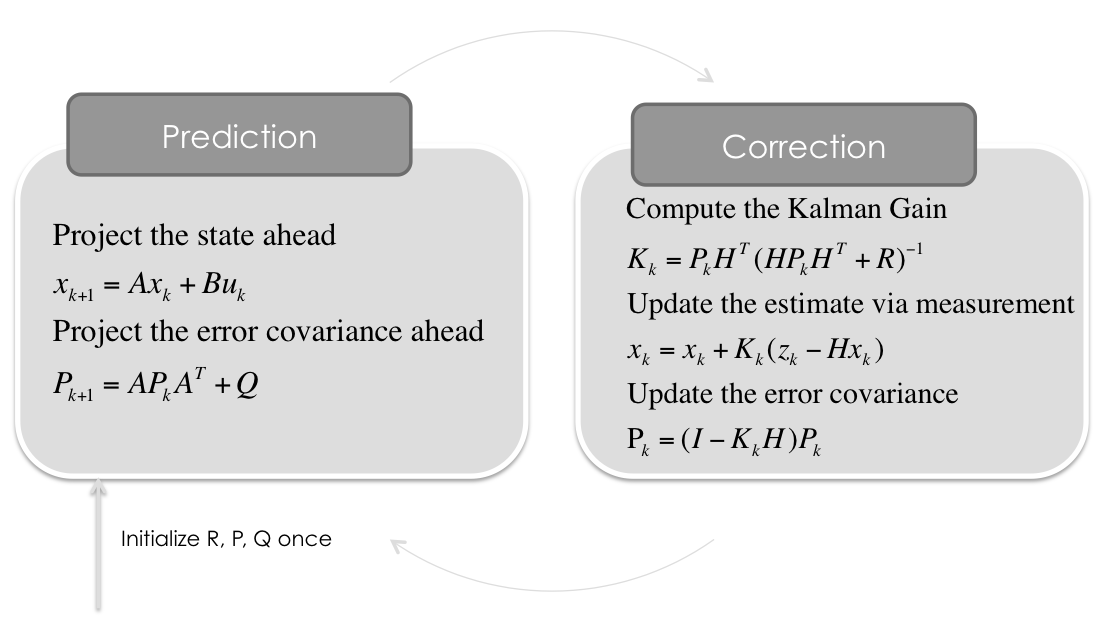
구현 내용
A. Predict:
a. X = A * X + B * u
b. P = A * P * AT * Q
B. Measurement
a. Y = Z — H * X
b. K = ( P * HT ) / ( ( H * P * HT ) + R )
C. Update
a. X = X + K * Y
b. P = ( I — K * H ) * P
데이터 구조
For a row containing radar data, the columns are:
- sensor_type (R),
- rho_measured, phi_measured, rhodot_measured,
- timestamp,
- x_groundtruth, y_groundtruth, vx_groundtruth, vy_groundtruth, yaw_groundtruth, yawrate_groundtruth.
For a row containing lidar data, the columns are:
- sensor_type (L),
- x_measured, y_measured,
- timestamp,
- x_groundtruth, y_groundtruth, vx_groundtruth, vy_groundtruth, yaw_groundtruth, yawrate_groundtruth.
1. file Read
#**************Importing Required Libraries*************
import numpy as np
import pandas as pd
from numpy.linalg import inv
#*************Declare Variables**************************
#Read Input File
measurements = pd.read_csv('obj_pose-laser-radar-synthetic-input.txt', header=None, delim_whitespace = True, skiprows=1)
옵션 : ‘skiprows’ = 1
- 사전 정보 없음 `because, when we begin implementing KF algorithm, we don’t have any prior knowledge about state of vehicle. `
- 첫번쨰 reading은 기본으로 설정 `In such cases usually we default our state to first reading from sensor output. `
2. State X 정의
# Manualy copy initial readings from first row of input file.
prv_time = 1477010443000000/1000000.0
x = np.array([ #초기 입력값
[0.312242],
[0.5803398],
[0],
[0]
])
X값을 파일의 첫 줄로 설정
In below shown code, we will initialize our state X with reading from first row of input file.- And as this reading has already been used, we simply skip it while reading input file.
첫번째 입력 time을 previous Time으로 설정
Along with initial values of state vector X, we will also use first timestamp from input file as our previous time.- As explained in previous post, we need current and previous timestamps to calculate delta_t.
시간 단위는 ms이므로 10^6로 나눈
Timestamps provided are in unit microseconds, which we will divide by 10^6. This has two reasons,- 첫번째 이유 : 관리가 쉬움
first, a smaller number is easier to maintain. - 두번째 이유 : GT와 단위 맞추기
Second, the velocity groundtruth readings (and hence velocity values in our code) are in units of seconds
- 첫번째 이유 : 관리가 쉬움
3. GT & RMSE 정의
#Initialize variables to store ground truth and RMSE values
ground_truth = np.zeros([4, 1])
rmse = np.zeros([4, 1])
Next, we Initialize variables to store ground truth and RMSE values.
RMSE (Root Mean Square Error) is used to judge performance of our algorithm against ground truth values.
4. matrix P & A 정의
#Initialize matrices P and A
P = np.array([ #예측 불확실성
[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1000, 0],
[0, 0, 0, 1000]
])
A = np.array([ # kinematic equation
[1.0, 0, 1.0, 0],
[0, 1.0, 0, 1.0],
[0, 0, 1.0, 0],
[0, 0, 0, 1.0]
])
We initialize matrix P and A.
A = 속도x시간은 거리인 운동학적 공식
Basically matrix A is used to implement kinematics equations of distance, speed and time, andP = matrix P is State Covariance Matrix having variances in x, y, vx and vy as its diagonal elements.
P초기값의 의미
What this initial P values mean is that- we have high confidence in our positional values, indicated by relatively low variance value, and low confidence in velocity values, indicated by relatively large variance value.
5. Matrix H & I
H = np.array([ #크기 맞추기 위해 사용
[1.0, 0, 0, 0],
[0, 1.0, 0, 0]
])
I = np.identity(4)
z_lidar = np.zeros([2, 1]) # 입력값
Next we define H and I matrices, which, as I explained in last post, will be 4 x 2 and 4 x 4 matrices respectively.
Z : LIDAR 센서 값 We define vector Z, which, as our Lidar readings will consist of 2 positional readings (x and y), will be a 2 x 1 vector.
6. Matrix R
R = np.array([ #측정 불확실성
[0.0225, 0],
[0, 0.0225]
])
We define Measurement Covariance matrix R, which again, as per last post will be a 2 x 2 matrix.
We will talk more about how to get values for R matrix and noise_ax and noise_ay in future articles.
7. noise_ax, noise_ay and matrix Q.
Next we define noise_ax, noise_ay and matrix Q.
noise_ax = 5
noise_ay = 5
Q = np.zeros([4, 4])
kinematics공식을 보면 위치와 속도에 대하여 가속도 Factor가 사용되는것을 알수 있다. If we revisit kinematics equations, you can see that there is an acceleration factor in positional and velocity terms.
They have been rewritten here for ease.
Px(t+1) = Px + delta_t * vx + 0.5 * ax * delta_t²
Py(t+1) = Py + delta_t * vy + 0.5 * ay * delta_t²
Vx(t+1) = Vx + ax * delta_t
Vy(t+1) = Vy + ay * delta_t
가속도는 알려진 정보가 아니므로 noise를 더할수 있다. 그리고 이 무작위 noise는 .... Since the acceleration is unknown we can add it to the noise component, and this random noise would be expressed analytically as the last terms in the equation derived above.
따라서 Vector V는 아래와 같이 Zero Mean과 Covariance matrix Q로 구성 할수 있다. So, we have a random acceleration vector v in this form, which is described by a zero mean and a covariance matrix Q.

Vector V는 다시 두개의 컴포넌트로 분리 가능하다. The vector v can be decomposed into two components
G: a 4 by 2 matrix G which does not contain random variables anda: a 2 by 1 matrix a which contains the random acceleration components:

delta_tis calculated at each iteration of Kalman Filter,- and as we don’t have any acceleration data, we define
acceleration- a as random vector with zero mean and
- standard deviations noise_ax & noise_ay
covariance matrix Q
Based on our noise vector we can define now the new covariance matrix Q.
The covariance matrix is defined as the expectation value of the noise vector v times the noise vector v transpose.
So let’s write this down:

As G does not contain random variables, we can put it outside the expectation calculation

ax and ay are assumed to be uncorrelated noise processes.
- This means that the covariance
sigma_axy in Qis zero.

So after combining everything in one matrix we obtain our 4 by 4 Q matrix:

At each iteration of Kalman Filter, we will be calculating matrix Q as per above formula.
8. 칼만필터 적용
이제 모든 변수가 준비 되었으니 매 센서 데이터 수신시 칼만필터를 적용해 보 With all our variables defined, let’s begin with iterating through sensor data and applying Kalman Filter on them.
8.1 측정값 읽기
#**********************Iterate through main loop********************
#Begin iterating through sensor data
for i in range (len(measurements)):
new_measurement = measurements.iloc[i, :].values
if new_measurement[0] == 'L':
라이다를 의미하는 L까지 측정값 읽기 Running a for loop till length of measurements, reading measurement line, checking if it’s a Lidar (‘L’) reading.
8.2 시간 정보 처리
#Calculate Timestamp and its power variables
cur_time = new_measurement[3]/1000000.0
dt = cur_time - prv_time
prv_time = cur_time
시간 정보를 읽어 비교후에 대체 하기 Get timestamp from current reading, calculate change in time by comparing it with previous timestamp and then replace current timestamp as previous timestamp for next iteration.
8.3 delta T계산 (Matrix Q계산시 필요)
dt_2 = dt * dt
dt_3 = dt_2 * dt
dt_4 = dt_3 * dt
Calculate delta_t’s (‘dt’ in code) square, cube , and 4th power of delta_t which are required to calculate Q matrix.
8.4 Matrix A 업데이트
#Updating matrix A with dt value
A[0][2] = dt
A[1][3] = dt
Updating matrix A with delta_t value.
Delta_t will be multiplied by velocity to come up with positional values.
8.5 Matrix Q 업데이트
#Updating Q matrix
Q[0][0] = dt_4/4*noise_ax
Q[0][2] = dt_3/2*noise_ax
Q[1][1] = dt_4/4*noise_ay
Q[1][3] = dt_3/2*noise_ay
Q[2][0] = dt_3/2*noise_ax
Q[2][2] = dt_2*noise_ax
Q[3][1] = dt_3/2*noise_ay
Q[3][3] = dt_2*noise_ay
#Updating sensor readings
z_lidar[0][0] = new_measurement[1]
z_lidar[1][0] = new_measurement[2]
#Collecting ground truths
ground_truth[0] = new_measurement[4]
ground_truth[1] = new_measurement[5]
ground_truth[2] = new_measurement[6]
ground_truth[3] = new_measurement[7]
Updating Q matrix.
If you look back at above derived equations for Q matrix, you can easil corelate below provided lines of code with that.
8.6 Call Predict & update
predict()
update(z_lidar)
And finally call Predict and Update functions.
9. Predict()
Now lets have a look at our predict() function which would very much similar to the following predict equations that we been using in this series.
A. Predict
a. X = A * X + B * u
b. P = A * P * AT * Q
Not much to explain in the code section, its really just a direct replica of derived formulas.
#**********************Define Functions*****************************
def predict():
# Predict Step
global x, P, Q
x = np.matmul(A, x)
At = np.transpose(A)
P = np.add(np.matmul(A, np.matmul(P, At)), Q)
10. update()
Moving ahead to define update() function.
We will be implementing both ‘measurement’ and ‘update’ steps in this function.
B. Measurement
a. Y = Z — H * X
b. K = ( P * HT ) / ( ( H * P * HT ) + R )
C. Update
a. X = X + K * Y
b. P = ( I — K * H ) * P
def update(z):
global x, P
# Measurement update step
Y = np.subtract(z_lidar, np.matmul(H, x))
Ht = np.transpose(H)
S = np.add(np.matmul(H, np.matmul(P, Ht)), R)
K = np.matmul(P, Ht)
Si = inv(S)
K = np.matmul(K, Si)
# New state
x = np.add(x, np.matmul(K, Y))
P = np.matmul(np.subtract(I ,np.matmul(K, H)), P)
결론
위 코드가 칼만 필터 기본 구조 이다.
The only difference in more advanced versions is the different kinematics and sensor equations they use.